 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirichlet process mixture model based on topologically augmented signal representation for clustering infant vocalizations
Jul 08, 2024Based on audio recordings made once a month during the first 12 months of a child's life, we propose a new method for clustering this set of vocalizations. We use a topologically augmented representation of the vocalizations, employing two persistence diagrams for each vocalization: one computed on the surface of its spectrogram and one on the Takens' embeddings of the vocalization. A synthetic persistent variable is derived for each diagram and added to the MFCCs (Mel-frequency cepstral coefficients). Using this representation, we fit a non-parametric Bayesian mixture model with a Dirichlet process prior to model the number of components. This procedure leads to a novel data-driven categorization of vocal productions. Our findings reveal the presence of 8 clusters of vocalizations, allowing us to compare their temporal distribution and acoustic profiles in the first 12 months of life.
Topological data analysis of human vowels: Persistent homologies across representation spaces
Oct 10, 2023Topological Data Analysis (TDA) has been successfully used for various tasks in signal/image processing, from visualization to supervised/unsupervised classification. Often, topological characteristics are obtained from persistent homology theory. The standard TDA pipeline starts from the raw signal data or a representation of it. Then, it consists in building a multiscale topological structure on the top of the data using a pre-specified filtration, and finally to compute the topological signature to be further exploited. The commonly used topological signature is a persistent diagram (or transformations of it). Current research discusses the consequences of the many ways to exploit topological signatures, much less often the choice of the filtration, but to the best of our knowledge, the choice of the representation of a signal has not been the subject of any study yet. This paper attempts to provide some answers on the latter problem. To this end, we collected real audio data and built a comparative study to assess the quality of the discriminant information of the topological signatures extracted from three different representation spaces. Each audio signal is represented as i) an embedding of observed data in a higher dimensional space using Taken's representation, ii) a spectrogram viewed as a surface in a 3D ambient space, iii) the set of spectrogram's zeroes. From vowel audio recordings, we use topological signature for three prediction problems: speaker gender, vowel type, and individual. We show that topologically-augmented random forest improves the Out-of-Bag Error (OOB) over solely based Mel-Frequency Cepstral Coefficients (MFCC) for the last two problems. Our results also suggest that the topological information extracted from different signal representations is complementary, and that spectrogram's zeros offers the best improvement for gender prediction.
Detecting human and non-human vocal productions in large scale audio recordings
Feb 14, 2023
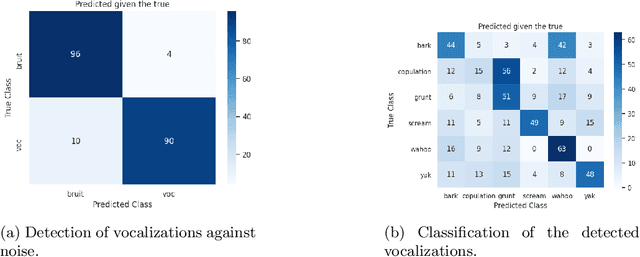

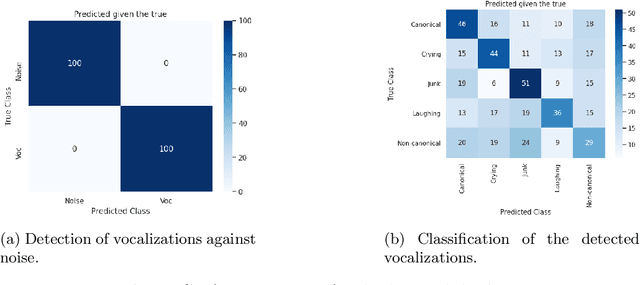
We propose an automatic data processing pipeline to extract vocal productions from large-scale natural audio recordings. Through a series of computational steps (windowing, creation of a noise class, data augmentation, re-sampling, transfer learning, Bayesian optimisation), it automatically trains a neural network for detecting various types of natural vocal productions in a noisy data stream without requiring a large sample of labeled data. We test it on two different data sets, one from a group of Guinea baboons recorded from a primate research center and one from human babies recorded at home. The pipeline trains a model on 72 and 77 minutes of labeled audio recordings, with an accuracy of 94.58% and 99.76%. It is then used to process 443 and 174 hours of natural continuous recordings and it creates two new databases of 38.8 and 35.2 hours, respectively. We discuss the strengths and limitations of this approach that can be applied to any massive audio recording.