 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable representation learning and retrieval for display advertising
Jan 04, 2021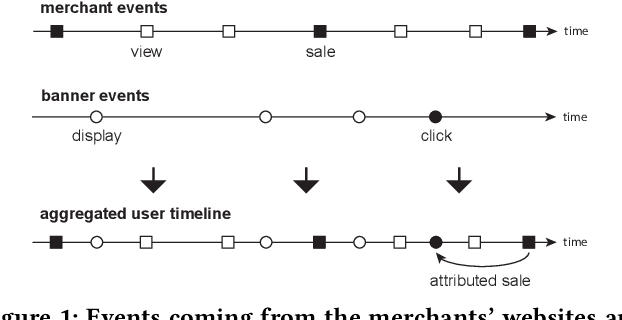

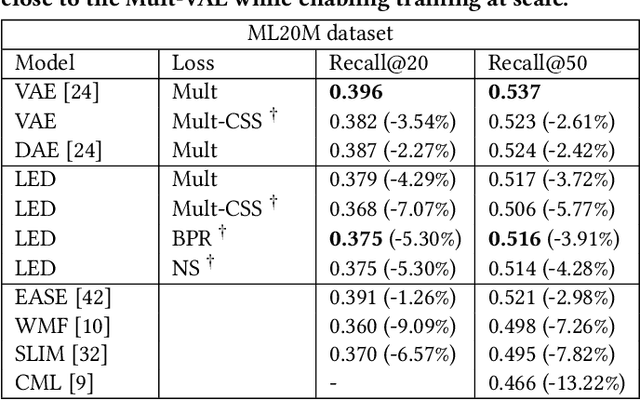
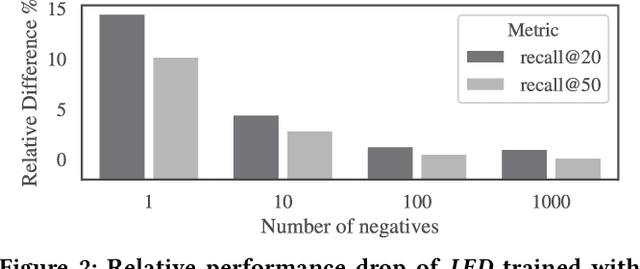
Over the past decades, recommendation has become a critical component of many online services such as media streaming and e-commerce. Recent advances in algorithms, evaluation methods and datasets have led to continuous improvements of the state-of-the-art. However, much work remains to be done to make these methods scale to the size of the internet. Online advertising offers a unique testbed for recommendation at scale. Every day, billions of users interact with millions of products in real-time. Systems addressing this scenario must work reliably at scale. We propose an efficient model (LED, for Lightweight Encoder-Decoder) reaching a new trade-off between complexity, scale and performance. Specifically, we show that combining large-scale matrix factorization with lightweight embedding fine-tuning unlocks state-of-the-art performance at scale. We further provide the detailed description of a system architecture and demonstrate its operation over two months at the scale of the internet. Our design allows serving billions of users across hundreds of millions of items in a few milliseconds using standard hardware.
Effective Feature Representation for Clinical Text Concept Extraction
Oct 31, 2018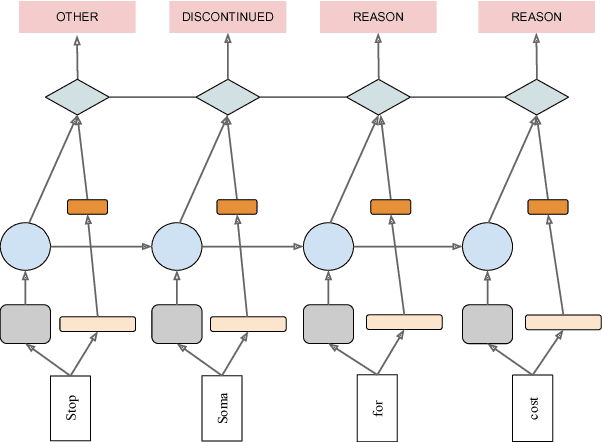


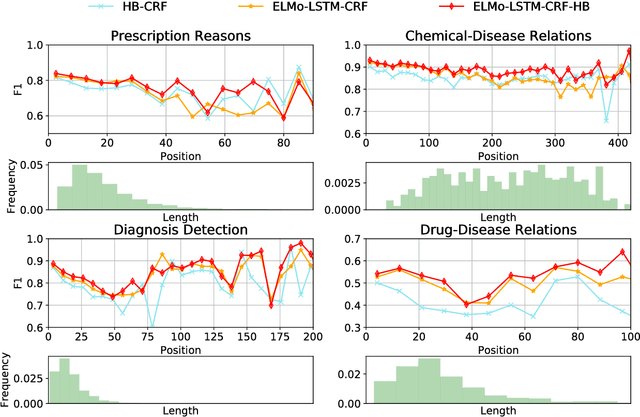
Crucial information about the practice of healthcare is recorded only in free-form text, which creates an enormous opportunity for high-impact NLP. However, annotated healthcare datasets tend to be small and expensive to obtain, which raises the question of how to make maximally efficient uses of the available data. To this end, we develop an LSTM-CRF model for combining unsupervised word representations and hand-built feature representations derived from publicly available healthcare ontologies. We show that this combined model yields superior performance on five datasets of diverse kinds of healthcare text (clinical, social, scientific, commercial). Each involves the labeling of complex, multi-word spans that pick out different healthcare concepts. We also introduce a new labeled dataset for identifying the treatment relations between drugs and diseases.