 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge transfer in deep block-modular neural networks
Jul 24, 2019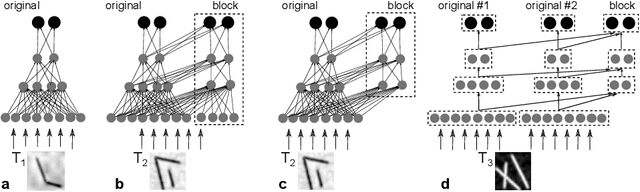



Although deep neural networks (DNNs) have demonstrated impressive results during the last decade, they remain highly specialized tools, which are trained -- often from scratch -- to solve each particular task. The human brain, in contrast, significantly re-uses existing capacities when learning to solve new tasks. In the current study we explore a block-modular architecture for DNNs, which allows parts of the existing network to be re-used to solve a new task without a decrease in performance when solving the original task. We show that networks with such architectures can outperform networks trained from scratch, or perform comparably, while having to learn nearly 10 times fewer weights than the networks trained from scratch.
Block Neural Network Avoids Catastrophic Forgetting When Learning Multiple Task
Nov 28, 2017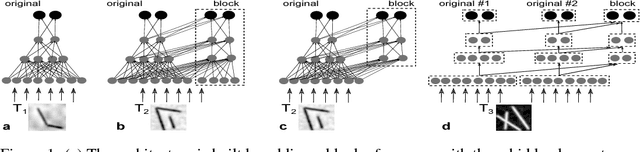


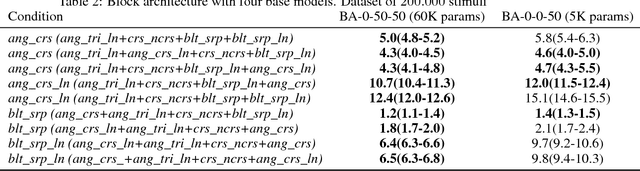
In the present work we propose a Deep Feed Forward network architecture which can be trained according to a sequential learning paradigm, where tasks of increasing difficulty are learned sequentially, yet avoiding catastrophic forgetting. The proposed architecture can re-use the features learned on previous tasks in a new task when the old tasks and the new one are related. The architecture needs fewer computational resources (neurons and connections) and less data for learning the new task than a network trained from scratch
Hyper-dimensional computing for a visual question-answering system that is trainable end-to-end
Nov 28, 2017
In this work we propose a system for visual question answering. Our architecture is composed of two parts, the first part creates the logical knowledge base given the image. The second part evaluates questions against the knowledge base. Differently from previous work, the knowledge base is represented using hyper-dimensional computing. This choice has the advantage that all the operations in the system, namely creating the knowledge base and evaluating the questions against it, are differentiable, thereby making the system easily trainable in an end-to-end fashion.
Gradual Tuning: a better way of Fine Tuning the parameters of a Deep Neural Network
Nov 28, 2017



In this paper we present an alternative strategy for fine-tuning the parameters of a network. We named the technique Gradual Tuning. Once trained on a first task, the network is fine-tuned on a second task by modifying a progressively larger set of the network's parameters. We test Gradual Tuning on different transfer learning tasks, using networks of different sizes trained with different regularization techniques. The result shows that compared to the usual fine tuning, our approach significantly reduces catastrophic forgetting of the initial task, while still retaining comparable if not better performance on the new task.