Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlock Neural Network Avoids Catastrophic Forgetting When Learning Multiple Task
Paper and Code
Nov 28, 2017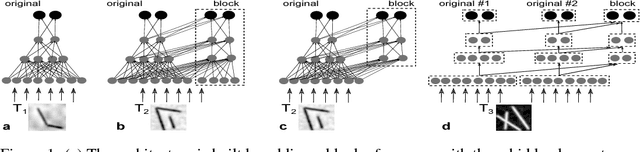


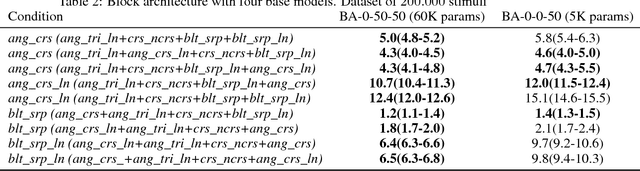
In the present work we propose a Deep Feed Forward network architecture which can be trained according to a sequential learning paradigm, where tasks of increasing difficulty are learned sequentially, yet avoiding catastrophic forgetting. The proposed architecture can re-use the features learned on previous tasks in a new task when the old tasks and the new one are related. The architecture needs fewer computational resources (neurons and connections) and less data for learning the new task than a network trained from scratch
View paper on