 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcessing Self Corrections in a speech to speech system
Aug 21, 2000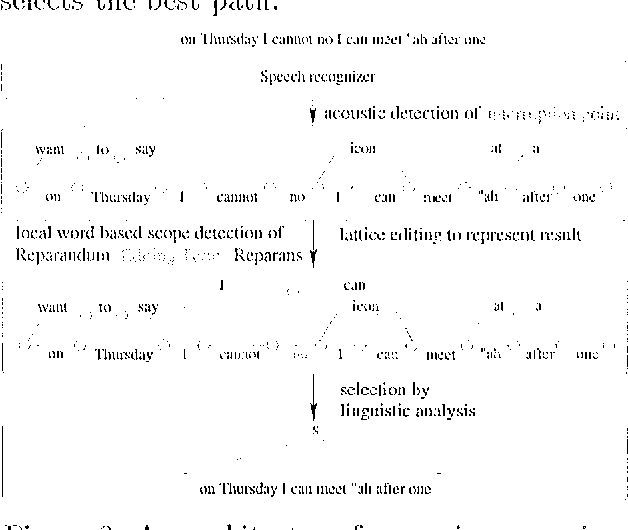
Speech repairs occur often in spontaneous spoken dialogues. The ability to detect and correct those repairs is necessary for any spoken language system. We present a framework to detect and correct speech repairs where all relevant levels of information, i.e., acoustics, lexis, syntax and semantics can be integrated. The basic idea is to reduce the search space for repairs as soon as possible by cascading filters that involve more and more features. At first an acoustic module generates hypotheses about the existence of a repair. Second a stochastic model suggests a correction for every hypothesis. Well scored corrections are inserted as new paths in the word lattice. Finally a lattice parser decides on accepting the rep air.
* 5 pages, 2 figures
Architectural Considerations for Conversational Systems -- The Verbmobil/INTARC Experience
Jul 14, 1999
The paper describes the speech to speech translation system INTARC, developed during the first phase of the Verbmobil project. The general design goals of the INTARC system architecture were time synchronous processing as well as incrementality and interactivity as a means to achieve a higher degree of robustness and scalability. Interactivity means that in addition to the bottom-up (in terms of processing levels) data flow the ability to process top-down restrictions considering the same signal segment for all processing levels. The construction of INTARC 2.0, which has been operational since fall 1996, followed an engineering approach focussing on the integration of symbolic (linguistic) and stochastic (recognition) techniques which led to a generalization of the concept of a ``one pass'' beam search.
Modelling Users, Intentions, and Structure in Spoken Dialog
Sep 17, 1998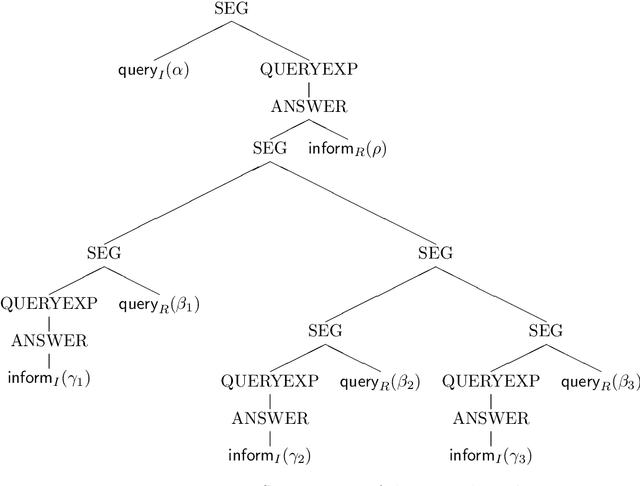


We outline how utterances in dialogs can be interpreted using a partial first order logic. We exploit the capability of this logic to talk about the truth status of formulae to define a notion of coherence between utterances and explain how this coherence relation can serve for the construction of AND/OR trees that represent the segmentation of the dialog. In a BDI model we formalize basic assumptions about dialog and cooperative behaviour of participants. These assumptions provide a basis for inferring speech acts from coherence relations between utterances and attitudes of dialog participants. Speech acts prove to be useful for determining dialog segments defined on the notion of completing expectations of dialog participants. Finally, we sketch how explicit segmentation signalled by cue phrases and performatives is covered by our dialog model.
Combining Expression and Content in Domains for Dialog Managers
Aug 13, 1998We present work in progress on abstracting dialog managers from their domain in order to implement a dialog manager development tool which takes (among other data) a domain description as input and delivers a new dialog manager for the described domain as output. Thereby we will focus on two topics; firstly, the construction of domain descriptions with description logics and secondly, the interpretation of utterances in a given domain.
* 5 pages, uses conference.sty
Robust Parsing of Spoken Dialogue Using Contextual Knowledge and Recognition Probabilities
May 08, 1995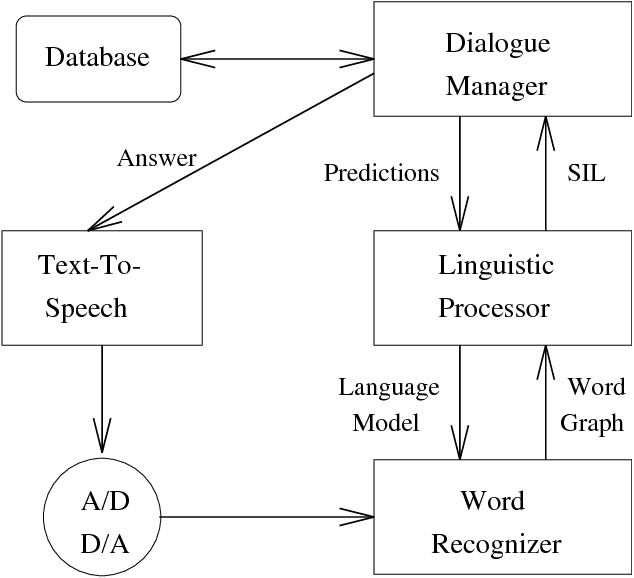
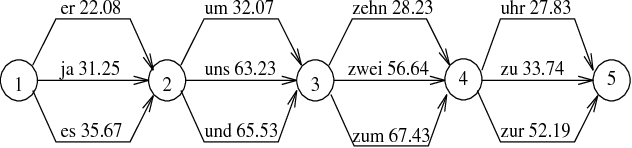
In this paper we describe the linguistic processor of a spoken dialogue system. The parser receives a word graph from the recognition module as its input. Its task is to find the best path through the graph. If no complete solution can be found, a robust mechanism for selecting multiple partial results is applied. We show how the information content rate of the results can be improved if the selection is based on an integrated quality score combining word recognition scores and context-dependent semantic predictions. Results of parsing word graphs with and without predictions are reported.
Anytime Algorithms for Speech Parsing?
Jun 21, 1994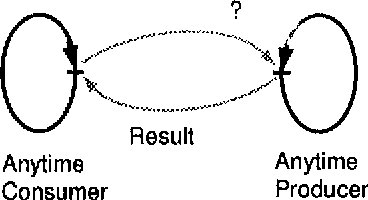
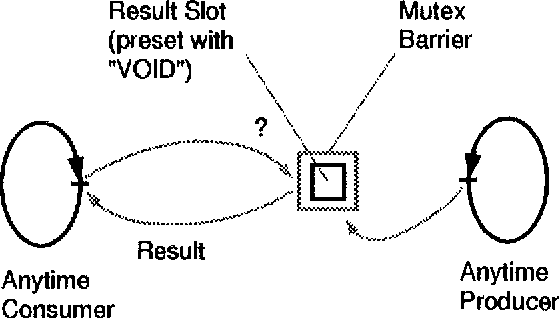
This paper discusses to which extent the concept of ``anytime algorithms'' can be applied to parsing algorithms with feature unification. We first try to give a more precise definition of what an anytime algorithm is. We arque that parsing algorithms have to be classified as contract algorithms as opposed to (truly) interruptible algorithms. With the restriction that the transaction being active at the time an interrupt is issued has to be completed before the interrupt can be executed, it is possible to provide a parser with limited anytime behavior, which is in fact being realized in our research prototype.
* 5 pages, 2 figures