 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSufficient Decision Proxies for Decision-Focused Learning
May 06, 2025When solving optimization problems under uncertainty with contextual data, utilizing machine learning to predict the uncertain parameters is a popular and effective approach. Decision-focused learning (DFL) aims at learning a predictive model such that decision quality, instead of prediction accuracy, is maximized. Common practice here is to predict a single value for each uncertain parameter, implicitly assuming that there exists a (single-scenario) deterministic problem approximation (proxy) that is sufficient to obtain an optimal decision. Other work assumes the opposite, where the underlying distribution needs to be estimated. However, little is known about when either choice is valid. This paper investigates for the first time problem properties that justify using either assumption. Using this, we present effective decision proxies for DFL, with very limited compromise on the complexity of the learning task. We show the effectiveness of presented approaches in experiments on problems with continuous and discrete variables, as well as uncertainty in the objective function and in the constraints.
To the Max: Reinventing Reward in Reinforcement Learning
Feb 02, 2024
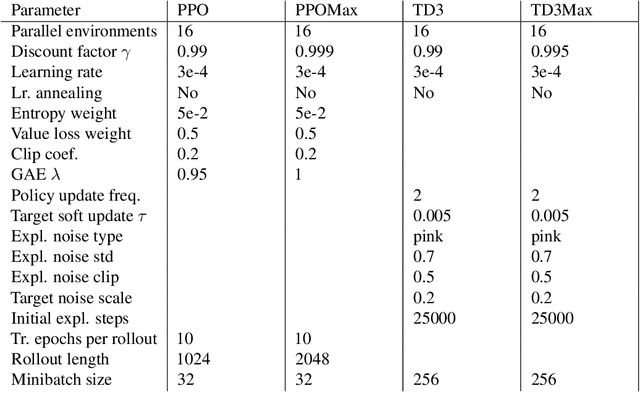

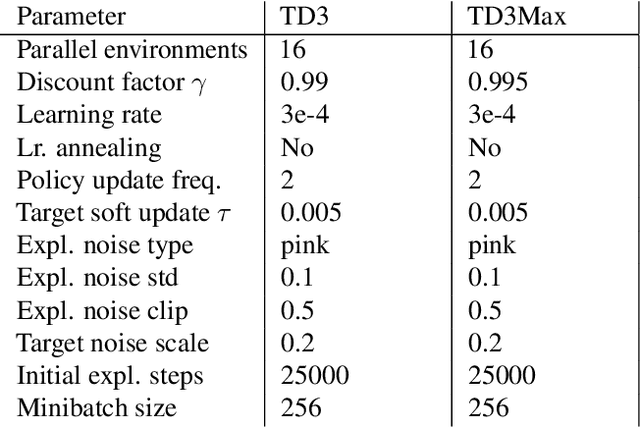
In reinforcement learning (RL), different rewards can define the same optimal policy but result in drastically different learning performance. For some, the agent gets stuck with a suboptimal behavior, and for others, it solves the task efficiently. Choosing a good reward function is hence an extremely important yet challenging problem. In this paper, we explore an alternative approach to using rewards for learning. We introduce max-reward RL, where an agent optimizes the maximum rather than the cumulative reward. Unlike earlier works, our approach works for deterministic and stochastic environments and can be easily combined with state-of-the-art RL algorithms. In the experiments, we study the performance of max-reward RL algorithms in two goal-reaching environments from Gymnasium-Robotics and demonstrate its benefits over standard RL. The code is publicly available.
You Shall not Pass: the Zero-Gradient Problem in Predict and Optimize for Convex Optimization
Jul 30, 2023Predict and optimize is an increasingly popular decision-making paradigm that employs machine learning to predict unknown parameters of optimization problems. Instead of minimizing the prediction error of the parameters, it trains predictive models using task performance as a loss function. In the convex optimization domain, predict and optimize has seen significant progress due to recently developed methods for differentiating optimization problem solutions over the problem parameters. This paper identifies a yet unnoticed drawback of this approach -- the zero-gradient problem -- and introduces a method to solve it. The suggested method is based on the mathematical properties of differential optimization and is verified using two real-world benchmarks.