 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikeGraphormer: A High-Performance Graph Transformer with Spiking Graph Attention
Mar 21, 2024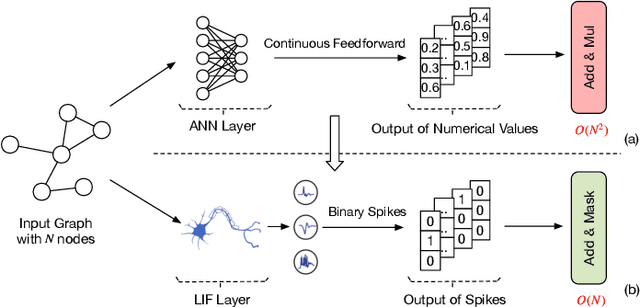

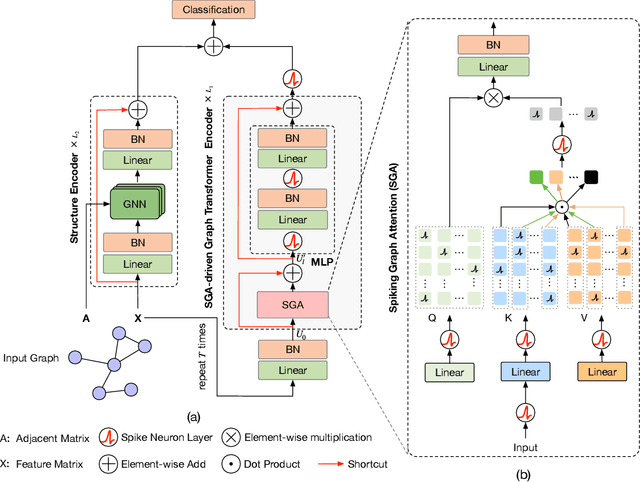

Recently, Graph Transformers have emerged as a promising solution to alleviate the inherent limitations of Graph Neural Networks (GNNs) and enhance graph representation performance. Unfortunately, Graph Transformers are computationally expensive due to the quadratic complexity inherent in self-attention when applied over large-scale graphs, especially for node tasks. In contrast, spiking neural networks (SNNs), with event-driven and binary spikes properties, can perform energy-efficient computation. In this work, we propose a novel insight into integrating SNNs with Graph Transformers and design a Spiking Graph Attention (SGA) module. The matrix multiplication is replaced by sparse addition and mask operations. The linear complexity enables all-pair node interactions on large-scale graphs with limited GPU memory. To our knowledge, our work is the first attempt to introduce SNNs into Graph Transformers. Furthermore, we design SpikeGraphormer, a Dual-branch architecture, combining a sparse GNN branch with our SGA-driven Graph Transformer branch, which can simultaneously perform all-pair node interactions and capture local neighborhoods. SpikeGraphormer consistently outperforms existing state-of-the-art approaches across various datasets and makes substantial improvements in training time, inference time, and GPU memory cost (10 ~ 20x lower than vanilla self-attention). It also performs well in cross-domain applications (image and text classification). We release our code at https://github.com/PHD-lanyu/SpikeGraphormer.