 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFused Extended Two-Way Fixed Effects for Difference-in-Differences with Staggered Adoptions
Dec 10, 2023To address the bias of the canonical two-way fixed effects estimator for difference-in-differences under staggered adoptions, Wooldridge (2021) proposed the extended two-way fixed effects estimator, which adds many parameters. However, this reduces efficiency. Restricting some of these parameters to be equal helps, but ad hoc restrictions may reintroduce bias. We propose a machine learning estimator with a single tuning parameter, fused extended two-way fixed effects (FETWFE), that enables automatic data-driven selection of these restrictions. We prove that under an appropriate sparsity assumption FETWFE identifies the correct restrictions with probability tending to one. We also prove the consistency, asymptotic normality, and oracle efficiency of FETWFE for two classes of heterogeneous marginal treatment effect estimators under either conditional or marginal parallel trends, and we prove consistency for two classes of conditional average treatment effects under conditional parallel trends. We demonstrate FETWFE in simulation studies and an empirical application.
Predicting Rare Events by Shrinking Towards Proportional Odds
May 30, 2023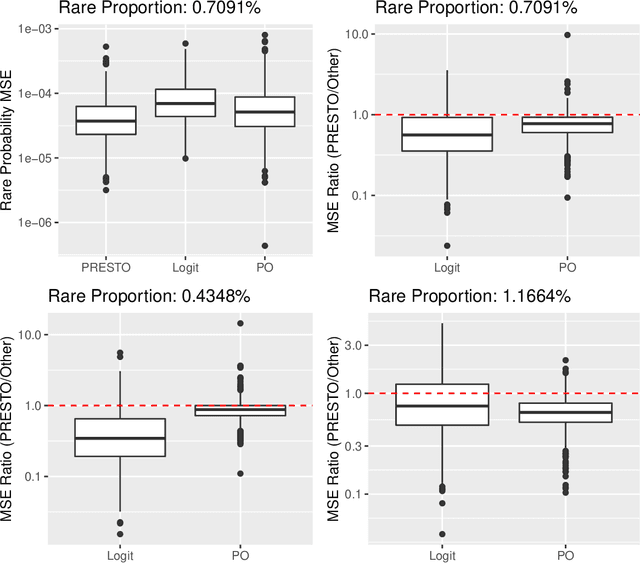

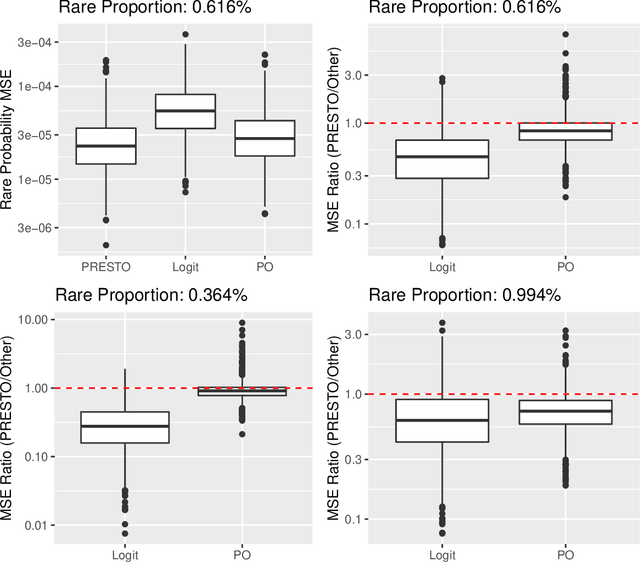

Training classifiers is difficult with severe class imbalance, but many rare events are the culmination of a sequence with much more common intermediate outcomes. For example, in online marketing a user first sees an ad, then may click on it, and finally may make a purchase; estimating the probability of purchases is difficult because of their rarity. We show both theoretically and through data experiments that the more abundant data in earlier steps may be leveraged to improve estimation of probabilities of rare events. We present PRESTO, a relaxation of the proportional odds model for ordinal regression. Instead of estimating weights for one separating hyperplane that is shifted by separate intercepts for each of the estimated Bayes decision boundaries between adjacent pairs of categorical responses, we estimate separate weights for each of these transitions. We impose an L1 penalty on the differences between weights for the same feature in adjacent weight vectors in order to shrink towards the proportional odds model. We prove that PRESTO consistently estimates the decision boundary weights under a sparsity assumption. Synthetic and real data experiments show that our method can estimate rare probabilities in this setting better than both logistic regression on the rare category, which fails to borrow strength from more abundant categories, and the proportional odds model, which is too inflexible.
Cluster Stability Selection
Jan 03, 2022
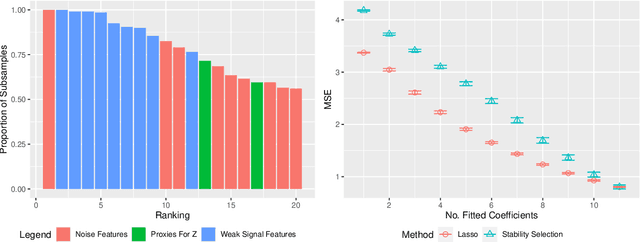
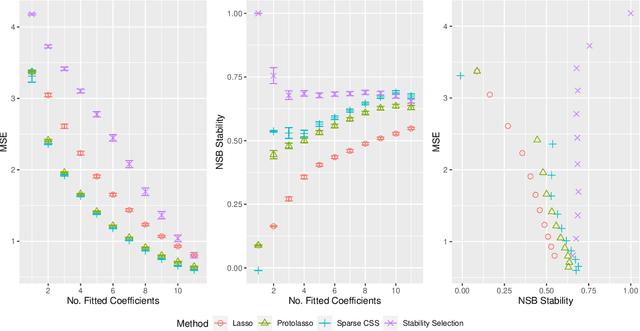
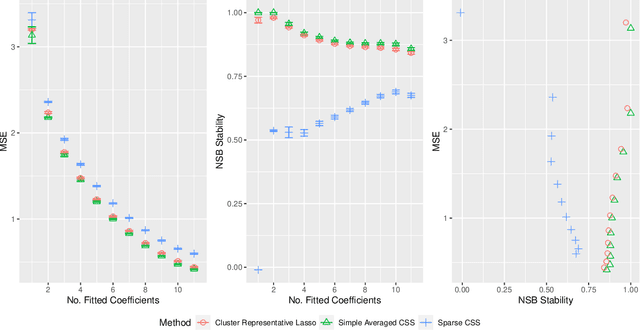
Stability selection (Meinshausen and Buhlmann, 2010) makes any feature selection method more stable by returning only those features that are consistently selected across many subsamples. We prove (in what is, to our knowledge, the first result of its kind) that for data containing highly correlated proxies for an important latent variable, the lasso typically selects one proxy, yet stability selection with the lasso can fail to select any proxy, leading to worse predictive performance than the lasso alone. We introduce cluster stability selection, which exploits the practitioner's knowledge that highly correlated clusters exist in the data, resulting in better feature rankings than stability selection in this setting. We consider several feature-combination approaches, including taking a weighted average of the features in each important cluster where weights are determined by the frequency with which cluster members are selected, which we show leads to better predictive models than previous proposals. We present generalizations of theoretical guarantees from Meinshausen and Buhlmann (2010) and Shah and Samworth (2012) to show that cluster stability selection retains the same guarantees. In summary, cluster stability selection enjoys the best of both worlds, yielding a sparse selected set that is both stable and has good predictive performance.