 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Rare Events by Shrinking Towards Proportional Odds
Paper and Code
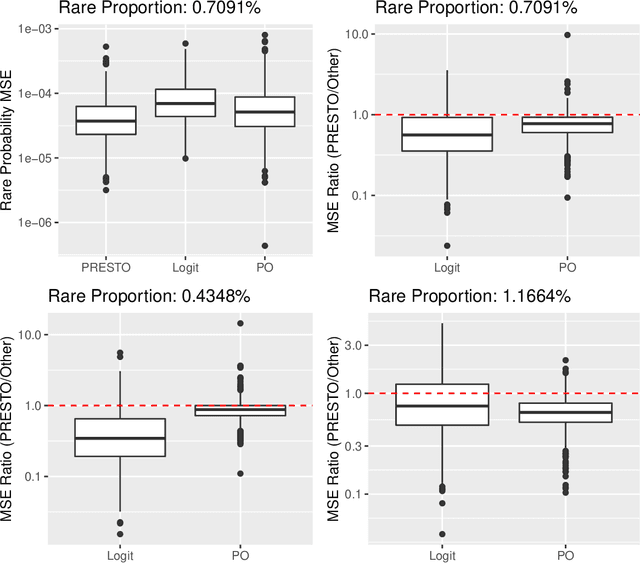

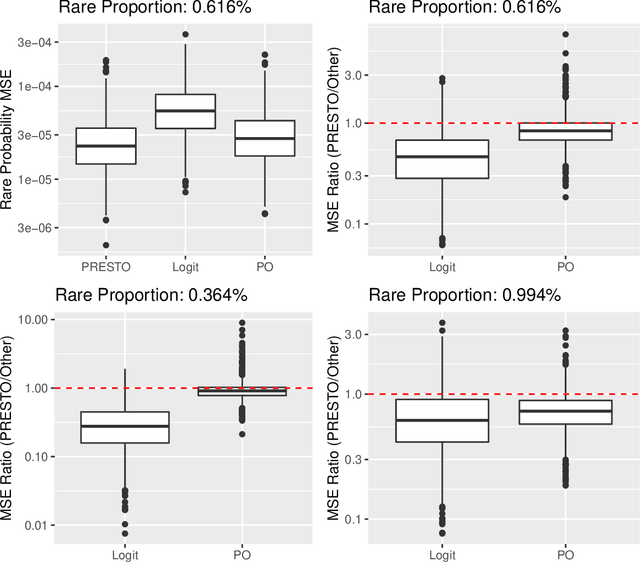

Training classifiers is difficult with severe class imbalance, but many rare events are the culmination of a sequence with much more common intermediate outcomes. For example, in online marketing a user first sees an ad, then may click on it, and finally may make a purchase; estimating the probability of purchases is difficult because of their rarity. We show both theoretically and through data experiments that the more abundant data in earlier steps may be leveraged to improve estimation of probabilities of rare events. We present PRESTO, a relaxation of the proportional odds model for ordinal regression. Instead of estimating weights for one separating hyperplane that is shifted by separate intercepts for each of the estimated Bayes decision boundaries between adjacent pairs of categorical responses, we estimate separate weights for each of these transitions. We impose an L1 penalty on the differences between weights for the same feature in adjacent weight vectors in order to shrink towards the proportional odds model. We prove that PRESTO consistently estimates the decision boundary weights under a sparsity assumption. Synthetic and real data experiments show that our method can estimate rare probabilities in this setting better than both logistic regression on the rare category, which fails to borrow strength from more abundant categories, and the proportional odds model, which is too inflexible.