 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Severely Deformed Mesh Reconstruction (DMR) from a Single-View Image
Jan 23, 2022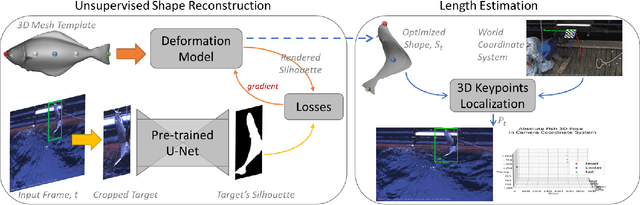



Much progress has been made in the supervised learning of 3D reconstruction of rigid objects from multi-view images or a video. However, it is more challenging to reconstruct severely deformed objects from a single-view RGB image in an unsupervised manner. Although training-based methods, such as specific category-level training, have been shown to successfully reconstruct rigid objects and slightly deformed objects like birds from a single-view image, they cannot effectively handle severely deformed objects and neither can be applied to some downstream tasks in the real world due to the inconsistent semantic meaning of vertices, which are crucial in defining the adopted 3D templates of objects to be reconstructed. In this work, we introduce a template-based method to infer 3D shapes from a single-view image and apply the reconstructed mesh to a downstream task, i.e., absolute length measurement. Without using 3D ground truth, our method faithfully reconstructs 3D meshes and achieves state-of-the-art accuracy in a length measurement task on a severely deformed fish dataset.