 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFall Detection for Smart Living using YOLOv5
Aug 28, 2024
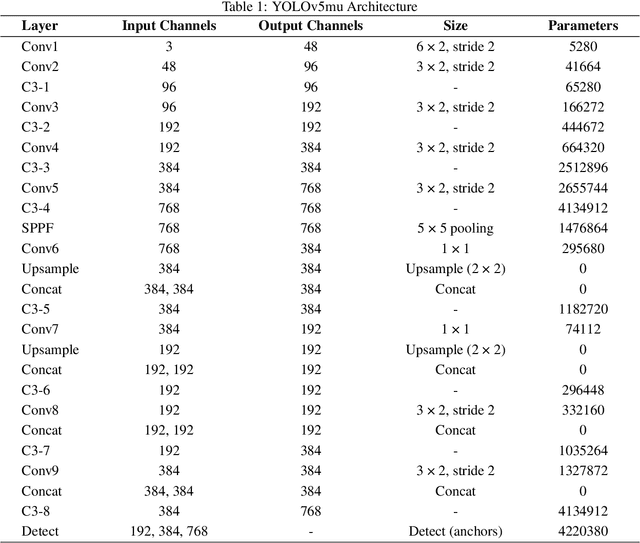


This work introduces a fall detection system using the YOLOv5mu model, which achieved a mean average precision (mAP) of 0.995, demonstrating exceptional accuracy in identifying fall events within smart home environments. Enhanced by advanced data augmentation techniques, the model demonstrates significant robustness and adaptability across various conditions. The integration of YOLOv5mu offers precise, real-time fall detection, which is crucial for improving safety and emergency response for residents. Future research will focus on refining the system by incorporating contextual data and exploring multi-sensor approaches to enhance its performance and practical applicability in diverse environments.
A Review of Transformer-Based Models for Computer Vision Tasks: Capturing Global Context and Spatial Relationships
Aug 27, 2024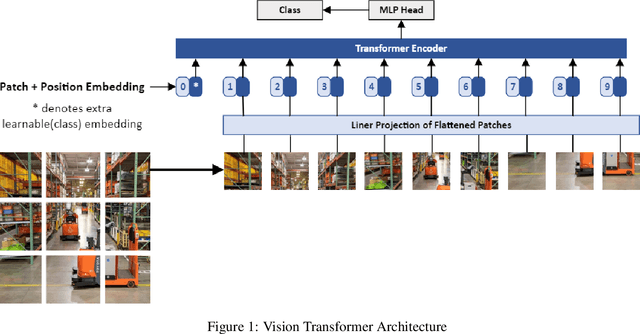
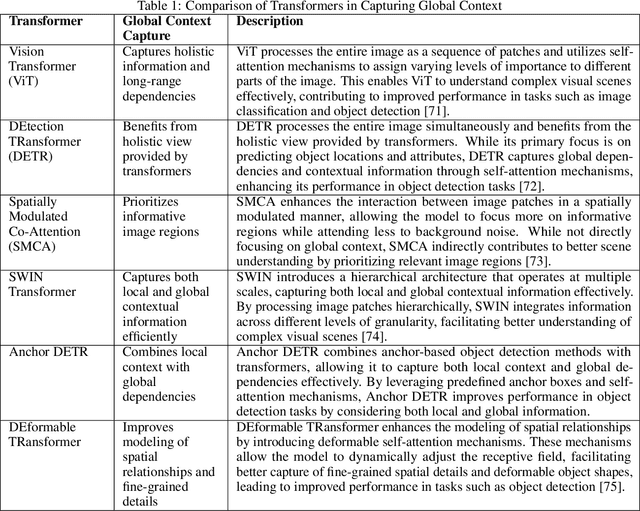
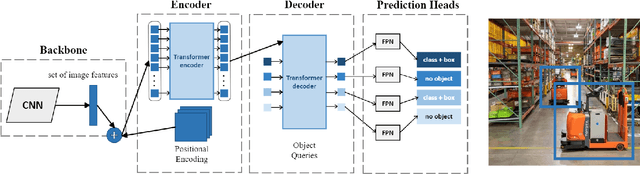
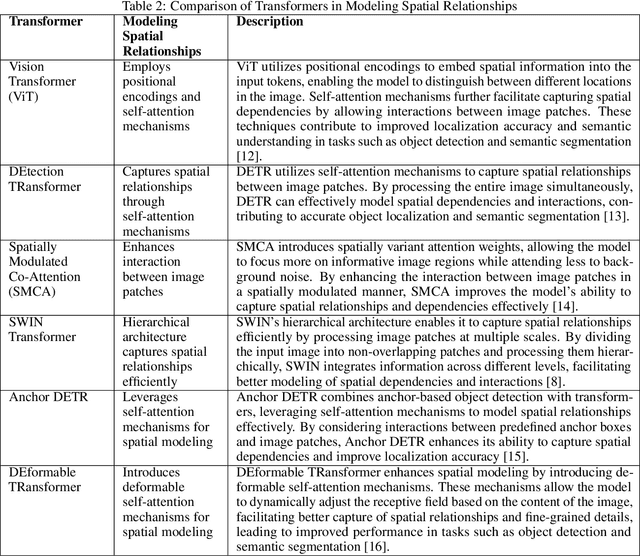
Transformer-based models have transformed the landscape of natural language processing (NLP) and are increasingly applied to computer vision tasks with remarkable success. These models, renowned for their ability to capture long-range dependencies and contextual information, offer a promising alternative to traditional convolutional neural networks (CNNs) in computer vision. In this review paper, we provide an extensive overview of various transformer architectures adapted for computer vision tasks. We delve into how these models capture global context and spatial relationships in images, empowering them to excel in tasks such as image classification, object detection, and segmentation. Analyzing the key components, training methodologies, and performance metrics of transformer-based models, we highlight their strengths, limitations, and recent advancements. Additionally, we discuss potential research directions and applications of transformer-based models in computer vision, offering insights into their implications for future advancements in the field.
Fall Detection for Industrial Setups Using YOLOv8 Variants
Aug 08, 2024



This paper presents the development of an industrial fall detection system utilizing YOLOv8 variants, enhanced by our proposed augmentation pipeline to increase dataset variance and improve detection accuracy. Among the models evaluated, the YOLOv8m model, consisting of 25.9 million parameters and 79.1 GFLOPs, demonstrated a respectable balance between computational efficiency and detection performance, achieving a mean Average Precision (mAP) of 0.971 at 50% Intersection over Union (IoU) across both "Fall Detected" and "Human in Motion" categories. Although the YOLOv8l and YOLOv8x models presented higher precision and recall, particularly in fall detection, their higher computational demands and model size make them less suitable for resource-constrained environments.