 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Transformer-Based Models for Computer Vision Tasks: Capturing Global Context and Spatial Relationships
Paper and Code
Aug 27, 2024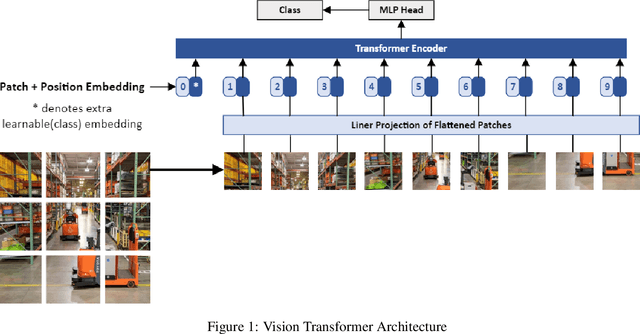
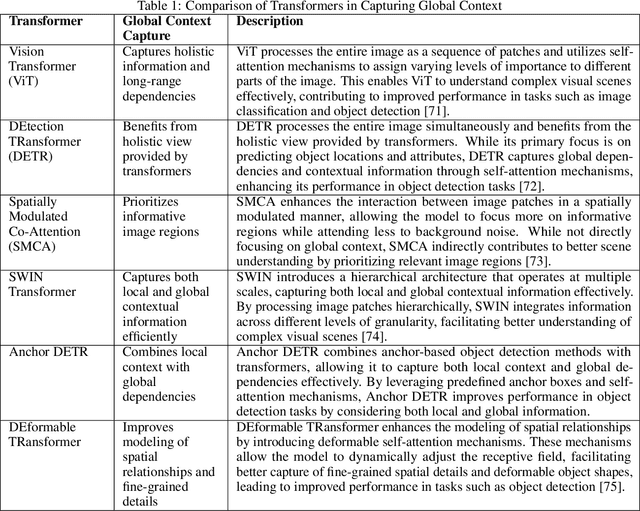
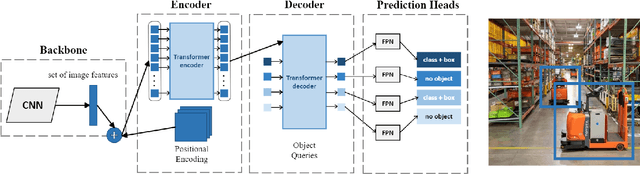
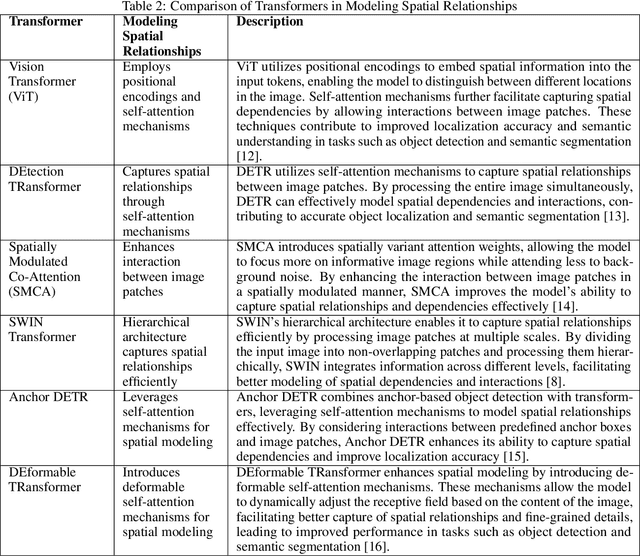
Transformer-based models have transformed the landscape of natural language processing (NLP) and are increasingly applied to computer vision tasks with remarkable success. These models, renowned for their ability to capture long-range dependencies and contextual information, offer a promising alternative to traditional convolutional neural networks (CNNs) in computer vision. In this review paper, we provide an extensive overview of various transformer architectures adapted for computer vision tasks. We delve into how these models capture global context and spatial relationships in images, empowering them to excel in tasks such as image classification, object detection, and segmentation. Analyzing the key components, training methodologies, and performance metrics of transformer-based models, we highlight their strengths, limitations, and recent advancements. Additionally, we discuss potential research directions and applications of transformer-based models in computer vision, offering insights into their implications for future advancements in the field.