 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Random Effects in Variational Autoencoders for Dimensionality Reduction of Correlated Data
Dec 24, 2024



Variational Autoencoders (VAE) are widely used for dimensionality reduction of large-scale tabular and image datasets, under the assumption of independence between data observations. In practice, however, datasets are often correlated, with typical sources of correlation including spatial, temporal and clustering structures. Inspired by the literature on linear mixed models (LMM), we propose LMMVAE -- a novel model which separates the classic VAE latent model into fixed and random parts. While the fixed part assumes the latent variables are independent as usual, the random part consists of latent variables which are correlated between similar clusters in the data such as nearby locations or successive measurements. The classic VAE architecture and loss are modified accordingly. LMMVAE is shown to improve squared reconstruction error and negative likelihood loss significantly on unseen data, with simulated as well as real datasets from various applications and correlation scenarios. It also shows improvement in the performance of downstream tasks such as supervised classification on the learned representations.
Integrating Random Effects in Deep Neural Networks
Jun 07, 2022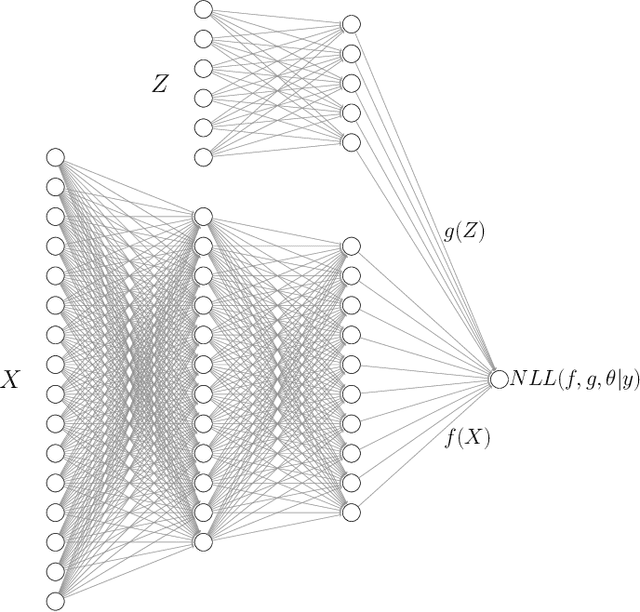



Modern approaches to supervised learning like deep neural networks (DNNs) typically implicitly assume that observed responses are statistically independent. In contrast, correlated data are prevalent in real-life large-scale applications, with typical sources of correlation including spatial, temporal and clustering structures. These correlations are either ignored by DNNs, or ad-hoc solutions are developed for specific use cases. We propose to use the mixed models framework to handle correlated data in DNNs. By treating the effects underlying the correlation structure as random effects, mixed models are able to avoid overfitted parameter estimates and ultimately yield better predictive performance. The key to combining mixed models and DNNs is using the Gaussian negative log-likelihood (NLL) as a natural loss function that is minimized with DNN machinery including stochastic gradient descent (SGD). Since NLL does not decompose like standard DNN loss functions, the use of SGD with NLL presents some theoretical and implementation challenges, which we address. Our approach which we call LMMNN is demonstrated to improve performance over natural competitors in various correlation scenarios on diverse simulated and real datasets. Our focus is on a regression setting and tabular datasets, but we also show some results for classification. Our code is available at https://github.com/gsimchoni/lmmnn.