 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGazeShift: Unsupervised Gaze Estimation and Dataset for VR
Mar 08, 2026Gaze estimation is instrumental in modern virtual reality (VR) systems. Despite significant progress in remote-camera gaze estimation, VR gaze research remains constrained by data scarcity - particularly the lack of large-scale, accurately labeled datasets captured with the off-axis camera configurations typical of modern headsets. Gaze annotation is difficult since fixation on intended targets cannot be guaranteed. To address these challenges, we introduce VRGaze - the first large-scale off-axis gaze estimation dataset for VR - comprising 2.1 million near-eye infrared images collected from 68 participants. We further propose GazeShift, an attention-guided unsupervised framework for learning gaze representations without labeled data. Unlike prior redirection-based methods that rely on multi-view or 3D geometry, GazeShift is tailored to near-eye infrared imagery, achieving effective gaze-appearance disentanglement in a compact, real-time model. GazeShift embeddings can be optionally adapted to individual users via lightweight few-shot calibration, achieving a 1.84-degree mean error on VRGaze. On the remote-camera MPIIGaze dataset, the model achieves a 7.15-degree person-agnostic error, doing so with 10x fewer parameters and 35x fewer FLOPs than baseline methods. Deployed natively on a VR headset GPU, inference takes only 5 ms. Combined with demonstrated robustness to illumination changes, these results highlight GazeShift as a label-efficient, real-time solution for VR gaze tracking. Project code and the VRGaze dataset are released at https://github.com/gazeshift3/gazeshift.
FaceCoresetNet: Differentiable Coresets for Face Set Recognition
Aug 27, 2023



In set-based face recognition, we aim to compute the most discriminative descriptor from an unbounded set of images and videos showing a single person. A discriminative descriptor balances two policies when aggregating information from a given set. The first is a quality-based policy: emphasizing high-quality and down-weighting low-quality images. The second is a diversity-based policy: emphasizing unique images in the set and down-weighting multiple occurrences of similar images as found in video clips which can overwhelm the set representation. This work frames face-set representation as a differentiable coreset selection problem. Our model learns how to select a small coreset of the input set that balances quality and diversity policies using a learned metric parameterized by the face quality, optimized end-to-end. The selection process is a differentiable farthest-point sampling (FPS) realized by approximating the non-differentiable Argmax operation with differentiable sampling from the Gumbel-Softmax distribution of distances. The small coreset is later used as queries in a self and cross-attention architecture to enrich the descriptor with information from the whole set. Our model is order-invariant and linear in the input set size. We set a new SOTA to set face verification on the IJB-B and IJB-C datasets. Our code is publicly available.
Knowing When to Quit: Selective Cascaded Regression with Patch Attention for Real-Time Face Alignment
Aug 03, 2021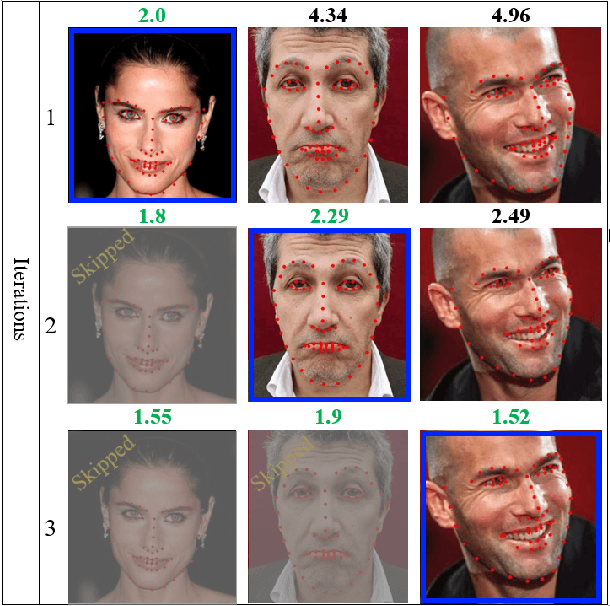
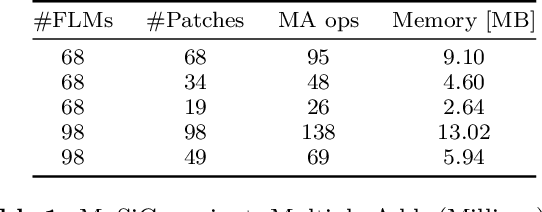
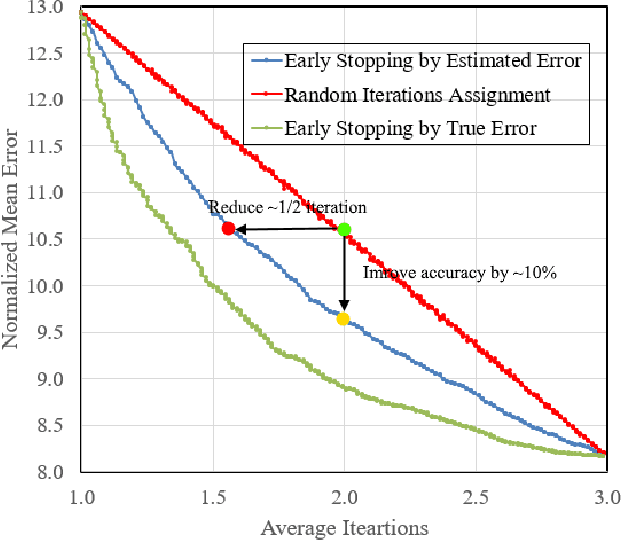
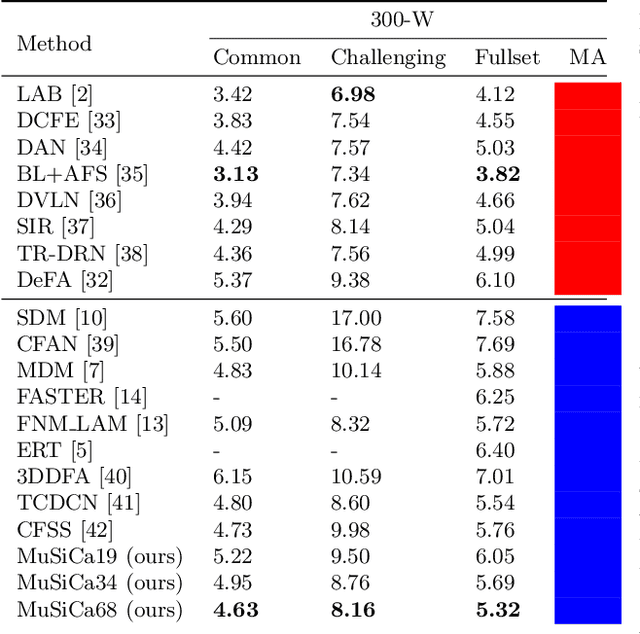
Facial landmarks (FLM) estimation is a critical component in many face-related applications. In this work, we aim to optimize for both accuracy and speed and explore the trade-off between them. Our key observation is that not all faces are created equal. Frontal faces with neutral expressions converge faster than faces with extreme poses or expressions. To differentiate among samples, we train our model to predict the regression error after each iteration. If the current iteration is accurate enough, we stop iterating, saving redundant iterations while keeping the accuracy in check. We also observe that as neighboring patches overlap, we can infer all facial landmarks (FLMs) with only a small number of patches without a major accuracy sacrifice. Architecturally, we offer a multi-scale, patch-based, lightweight feature extractor with a fine-grained local patch attention module, which computes a patch weighting according to the information in the patch itself and enhances the expressive power of the patch features. We analyze the patch attention data to infer where the model is attending when regressing facial landmarks and compare it to face attention in humans. Our model runs in real-time on a mobile device GPU, with 95 Mega Multiply-Add (MMA) operations, outperforming all state-of-the-art methods under 1000 MMA, with a normalized mean error of 8.16 on the 300W challenging dataset.
GPU-Based Computation of 2D Least Median of Squares with Applications to Fast and Robust Line Detection
Oct 05, 2015
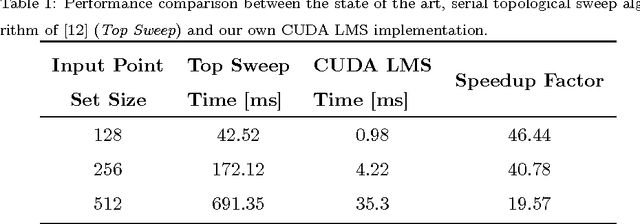
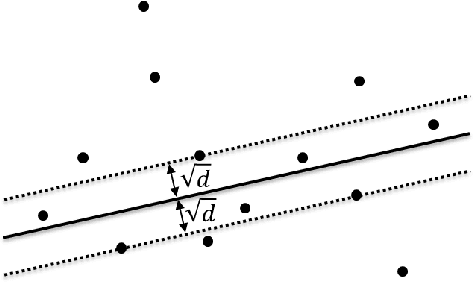

The 2D Least Median of Squares (LMS) is a popular tool in robust regression because of its high breakdown point: up to half of the input data can be contaminated with outliers without affecting the accuracy of the LMS estimator. The complexity of 2D LMS estimation has been shown to be $\Omega(n^2)$ where $n$ is the total number of points. This high theoretical complexity along with the availability of graphics processing units (GPU) motivates the development of a fast, parallel, GPU-based algorithm for LMS computation. We present a CUDA based algorithm for LMS computation and show it to be much faster than the optimal state of the art single threaded CPU algorithm. We begin by describing the proposed method and analyzing its performance. We then demonstrate how it can be used to modify the well-known Hough Transform (HT) in order to efficiently detect image lines in noisy images. Our method is compared with standard HT-based line detection methods and shown to overcome their shortcomings in terms of both efficiency and accuracy.