 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Statistical Approach for Synthetic EEG Data Generation
Apr 22, 2025Electroencephalogram (EEG) data is crucial for diagnosing mental health conditions but is costly and time-consuming to collect at scale. Synthetic data generation offers a promising solution to augment datasets for machine learning applications. However, generating high-quality synthetic EEG that preserves emotional and mental health signals remains challenging. This study proposes a method combining correlation analysis and random sampling to generate realistic synthetic EEG data. We first analyze interdependencies between EEG frequency bands using correlation analysis. Guided by this structure, we generate synthetic samples via random sampling. Samples with high correlation to real data are retained and evaluated through distribution analysis and classification tasks. A Random Forest model trained to distinguish synthetic from real EEG performs at chance level, indicating high fidelity. The generated synthetic data closely match the statistical and structural properties of the original EEG, with similar correlation coefficients and no significant differences in PERMANOVA tests. This method provides a scalable, privacy-preserving approach for augmenting EEG datasets, enabling more efficient model training in mental health research.
Stabilizing Machine Learning for Reproducible and Explainable Results: A Novel Validation Approach to Subject-Specific Insights
Dec 16, 2024

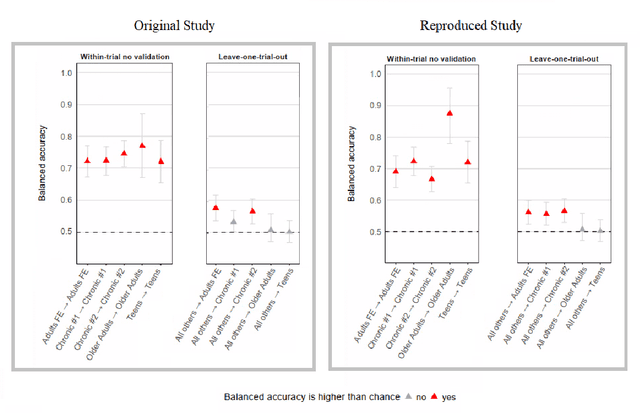

Machine Learning is transforming medical research by improving diagnostic accuracy and personalizing treatments. General ML models trained on large datasets identify broad patterns across populations, but their effectiveness is often limited by the diversity of human biology. This has led to interest in subject-specific models that use individual data for more precise predictions. However, these models are costly and challenging to develop. To address this, we propose a novel validation approach that uses a general ML model to ensure reproducible performance and robust feature importance analysis at both group and subject-specific levels. We tested a single Random Forest (RF) model on nine datasets varying in domain, sample size, and demographics. Different validation techniques were applied to evaluate accuracy and feature importance consistency. To introduce variability, we performed up to 400 trials per subject, randomly seeding the ML algorithm for each trial. This generated 400 feature sets per subject, from which we identified top subject-specific features. A group-specific feature importance set was then derived from all subject-specific results. We compared our approach to conventional validation methods in terms of performance and feature importance consistency. Our repeated trials approach, with random seed variation, consistently identified key features at the subject level and improved group-level feature importance analysis using a single general model. Subject-specific models address biological variability but are resource-intensive. Our novel validation technique provides consistent feature importance and improved accuracy within a general ML model, offering a practical and explainable alternative for clinical research.
Stress Monitoring Using Low-Cost Electroencephalogram Devices: A Systematic Literature Review
Feb 28, 2024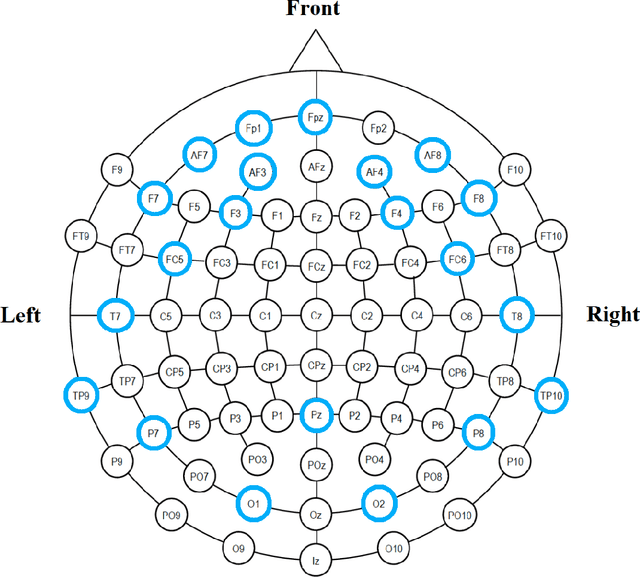

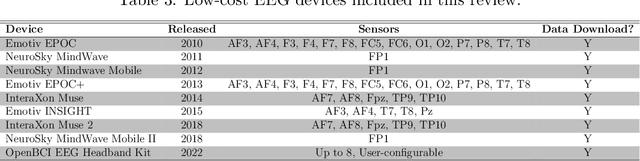
Introduction. Low-cost health monitoring devices are increasingly being used for mental health related studies including stress. While cortisol response magnitude remains the gold standard indicator for stress assessment, a growing number of studies have started to use low-cost EEG devices as primary recorders of biomarker data. Methods. This study reviews published works contributing and/or using EEG devices for detecting stress and their associated machine learning methods. The reviewed works are selected to answer three general research questions and are then synthesized into four categories of stress assessment using EEG, low-cost EEG devices, available datasets for EEG-based stress measurement, and machine learning techniques for EEG-based stress measurement. Results. A number of studies were identified where low-cost EEG devices were utilized to record brain function during phases of stress and relaxation. These studies generally reported a high predictive accuracy rate, verified using a number of different machine learning validation methods and statistical approaches. Of these studies, 60% can be considered low-powered studies based on the small number of test subjects used during experimentation. Conclusion. Low-cost consumer grade wearable devices including EEG and wrist-based monitors are increasingly being used in stress-related studies. Standardization of EEG signal processing and importance of sensor location still requires further study, and research in this area will continue to provide improvements as more studies become available.
Ensemble Machine Learning Model Trained on a New Synthesized Dataset Generalizes Well for Stress Prediction Using Wearable Devices
Sep 30, 2022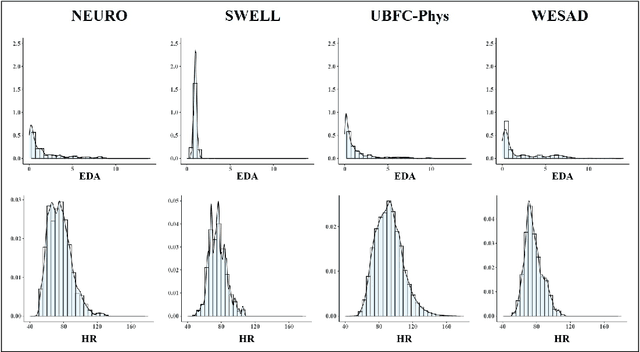
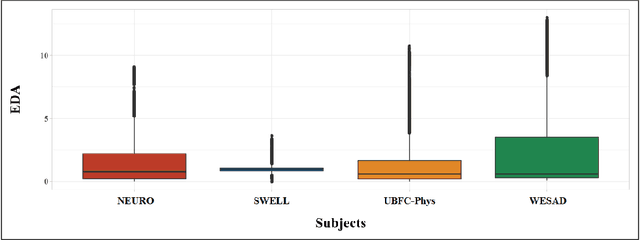
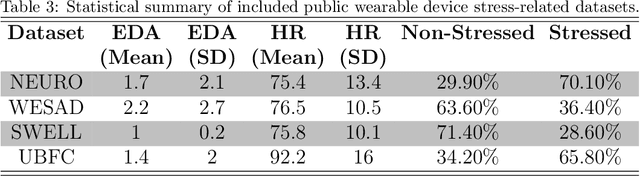
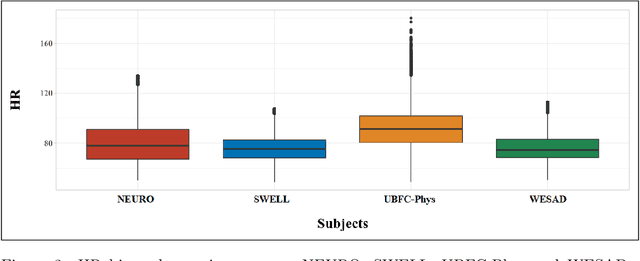
Introduction. We investigate the generalization ability of models built on datasets containing a small number of subjects, recorded in single study protocols. Next, we propose and evaluate methods combining these datasets into a single, large dataset. Finally, we propose and evaluate the use of ensemble techniques by combining gradient boosting with an artificial neural network to measure predictive power on new, unseen data. Methods. Sensor biomarker data from six public datasets were utilized in this study. To test model generalization, we developed a gradient boosting model trained on one dataset (SWELL), and tested its predictive power on two datasets previously used in other studies (WESAD, NEURO). Next, we merged four small datasets, i.e. (SWELL, NEURO, WESAD, UBFC-Phys), to provide a combined total of 99 subjects,. In addition, we utilized random sampling combined with another dataset (EXAM) to build a larger training dataset consisting of 200 synthesized subjects,. Finally, we developed an ensemble model that combines our gradient boosting model with an artificial neural network, and tested it on two additional, unseen publicly available stress datasets (WESAD and Toadstool). Results. Our method delivers a robust stress measurement system capable of achieving 85% predictive accuracy on new, unseen validation data, achieving a 25% performance improvement over single models trained on small datasets. Conclusion. Models trained on small, single study protocol datasets do not generalize well for use on new, unseen data and lack statistical power. Ma-chine learning models trained on a dataset containing a larger number of varied study subjects capture physiological variance better, resulting in more robust stress detection.
Machine Learning for Stress Monitoring from Wearable Devices: A Systematic Literature Review
Sep 29, 2022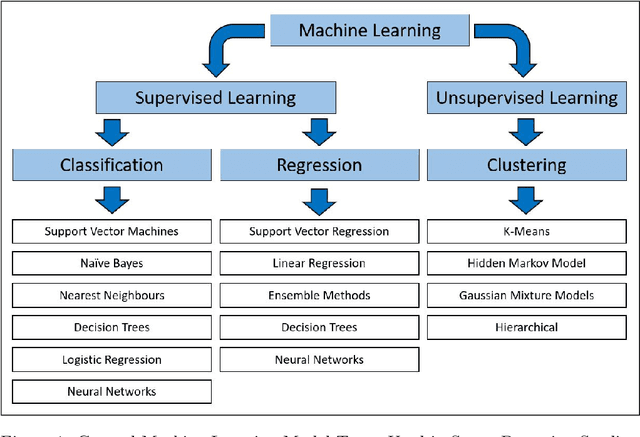
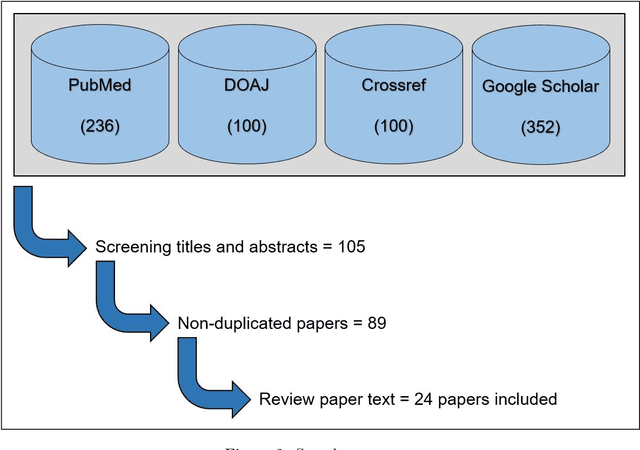
Introduction. The stress response has both subjective, psychological and objectively measurable, biological components. Both of them can be expressed differently from person to person, complicating the development of a generic stress measurement model. This is further compounded by the lack of large, labeled datasets that can be utilized to build machine learning models for accurately detecting periods and levels of stress. The aim of this review is to provide an overview of the current state of stress detection and monitoring using wearable devices, and where applicable, machine learning techniques utilized. Methods. This study reviewed published works contributing and/or using datasets designed for detecting stress and their associated machine learning methods, with a systematic review and meta-analysis of those that utilized wearable sensor data as stress biomarkers. The electronic databases of Google Scholar, Crossref, DOAJ and PubMed were searched for relevant articles and a total of 24 articles were identified and included in the final analysis. The reviewed works were synthesized into three categories of publicly available stress datasets, machine learning, and future research directions. Results. A wide variety of study-specific test and measurement protocols were noted in the literature. A number of public datasets were identified that are labeled for stress detection. In addition, we discuss that previous works show shortcomings in areas such as their labeling protocols, lack of statistical power, validity of stress biomarkers, and generalization ability. Conclusion. Generalization of existing machine learning models still require further study, and research in this area will continue to provide improvements as newer and more substantial datasets become available for study.