 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward General Analysis of Recursive Probability Models
Jan 10, 2013There is increasing interest within the research community in the design and use of recursive probability models. Although there still remains concern about computational complexity costs and the fact that computing exact solutions can be intractable for many nonrecursive models and impossible in the general case for recursive problems, several research groups are actively developing computational techniques for recursive stochastic languages. We have developed an extension to the traditional lambda-calculus as a framework for families of Turing complete stochastic languages. We have also developed a class of exact inference algorithms based on the traditional reductions of the lambda-calculus. We further propose that using the deBruijn notation (a lambda-calculus notation with nameless dummies) supports effective caching in such systems (caching being an essential component of efficient computation). Finally, our extension to the lambda-calculus offers a foundation and general theory for the construction of recursive stochastic modeling languages as well as promise for effective caching and efficient approximation algorithms for inference.
Language Without Words: A Pointillist Model for Natural Language Processing
Dec 11, 2012
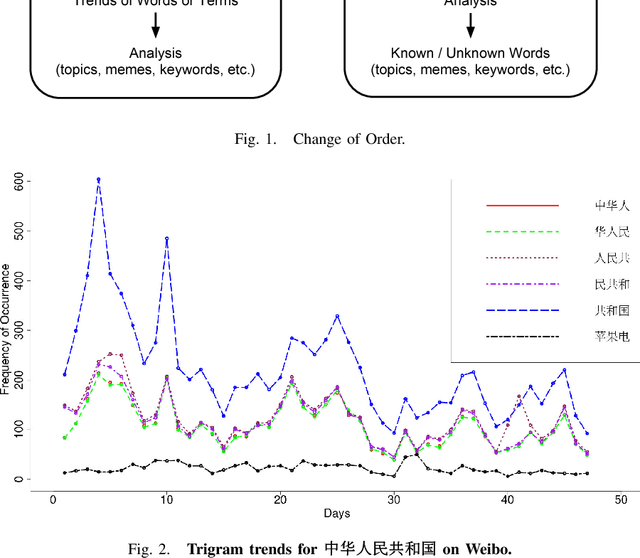
This paper explores two separate questions: Can we perform natural language processing tasks without a lexicon?; and, Should we? Existing natural language processing techniques are either based on words as units or use units such as grams only for basic classification tasks. How close can a machine come to reasoning about the meanings of words and phrases in a corpus without using any lexicon, based only on grams? Our own motivation for posing this question is based on our efforts to find popular trends in words and phrases from online Chinese social media. This form of written Chinese uses so many neologisms, creative character placements, and combinations of writing systems that it has been dubbed the "Martian Language." Readers must often use visual queues, audible queues from reading out loud, and their knowledge and understanding of current events to understand a post. For analysis of popular trends, the specific problem is that it is difficult to build a lexicon when the invention of new ways to refer to a word or concept is easy and common. For natural language processing in general, we argue in this paper that new uses of language in social media will challenge machines' abilities to operate with words as the basic unit of understanding, not only in Chinese but potentially in other languages.
* 5 pages, 2 figures