 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn filter design in deep convolutional neural network
Oct 29, 2024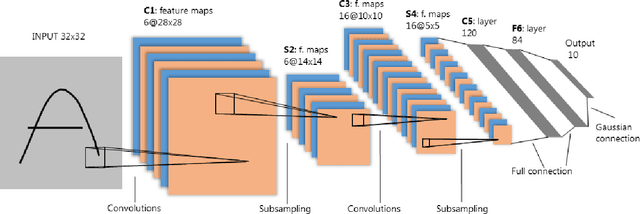

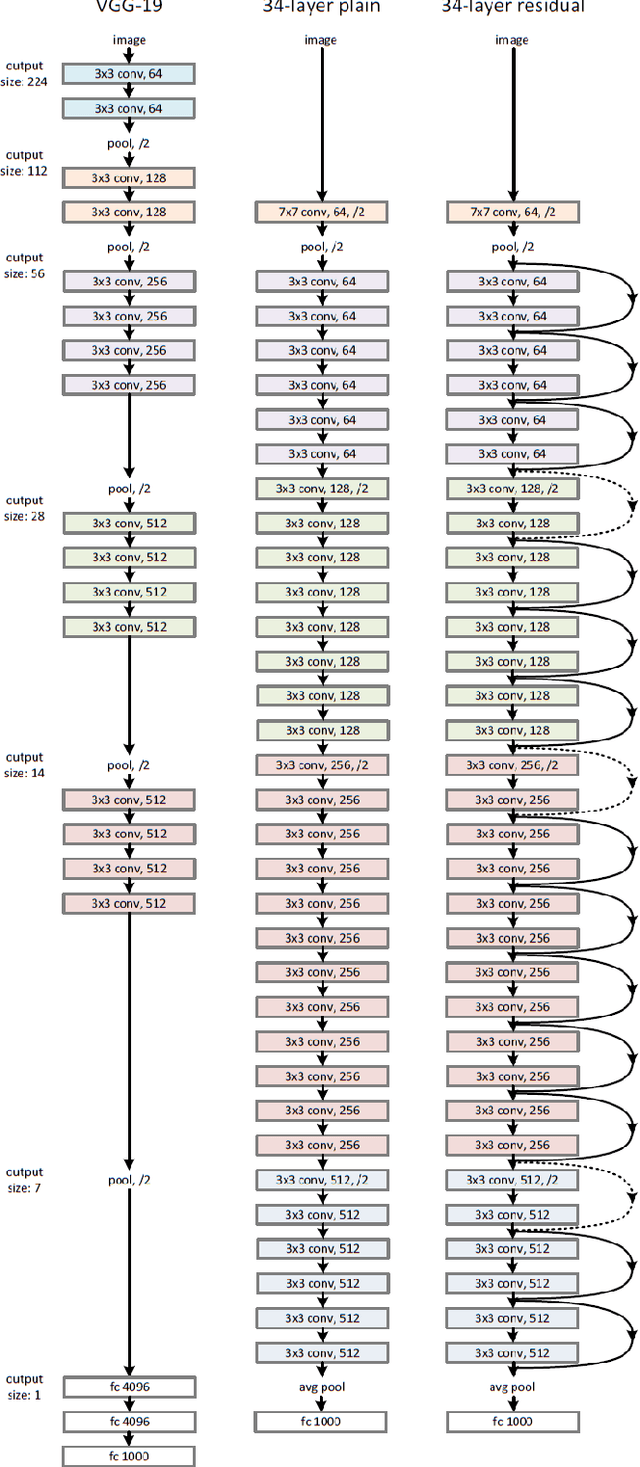

The deep convolutional neural network (DCNN) in computer vision has given promising results. It is widely applied in many areas, from medicine, agriculture, self-driving car, biometric system, and almost all computer vision-based applications. Filters or weights are the critical elements responsible for learning in DCNN. Backpropagation has been the primary learning algorithm for DCNN and provides promising results, but the size and numbers of the filters remain hyper-parameters. Various studies have been done in the last decade on semi-supervised, self-supervised, and unsupervised methods and their properties. The effects of filter initialization, size-shape selection, and the number of filters on learning and optimization have not been investigated in a separate publication to collate all the options. Such attributes are often treated as hyper-parameters and lack mathematical understanding. Computer vision algorithms have many limitations in real-life applications, and understanding the learning process is essential to have some significant improvement. To the best of our knowledge, no separate investigation has been published discussing the filters; this is our primary motivation. This study focuses on arguments for choosing specific physical parameters of filters, initialization, and learning technic over scattered methods. The promising unsupervised approaches have been evaluated. Additionally, the limitations, current challenges, and future scope have been discussed in this paper.