 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe GAN that Warped: Semantic Attribute Editing with Unpaired Data
Nov 30, 2018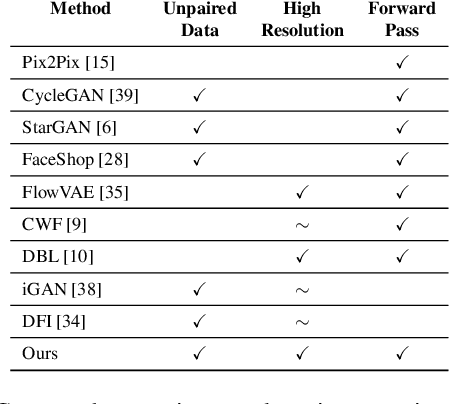
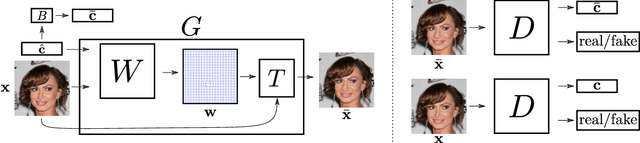
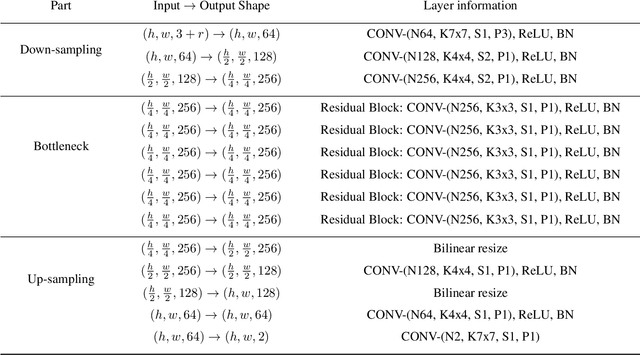

Deep neural networks have recently been used to edit images with great success. However, they are often limited by only being able to work at a restricted range of resolutions. They are also so flexible that semantic face edits can often result in an unwanted loss of identity. This work proposes a model that learns how to perform semantic image edits through the application of smooth warp fields. This warp field can be efficiently predicted at a reasonably low resolution and then resampled and applied at arbitrary resolutions. Previous approaches that attempted to use warping for semantic edits required paired data, that is example images of the same object with different semantic characteristics. In contrast, we employ recent advances in Generative Adversarial Networks that allow our model to be effectively trained with unpaired data. We demonstrate the efficacy of our method for editing face images at very high resolutions (4k images) with an efficient single forward pass of a deep network at a lower resolution. We illustrate how the extent of our edits can be trivially reduced or exaggerated by scaling the predicted warp field, and we also show that our edits are substantially better at maintaining the subject's identity.
Training VAEs Under Structured Residuals
Jul 31, 2018


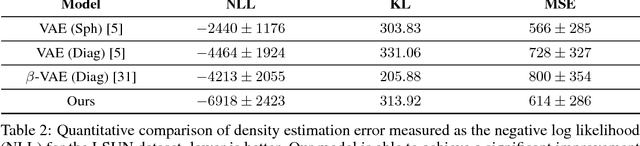
Variational auto-encoders (VAEs) are a popular and powerful deep generative model. Previous works on VAEs have assumed a factorized likelihood model, whereby the output uncertainty of each pixel is assumed to be independent. This approximation is clearly limited as demonstrated by observing a residual image from a VAE reconstruction, which often possess a high level of structure. This paper demonstrates a novel scheme to incorporate a structured Gaussian likelihood prediction network within the VAE that allows the residual correlations to be modeled. Our novel architecture, with minimal increase in complexity, incorporates the covariance matrix prediction within the VAE. We also propose a new mechanism for allowing structured uncertainty on color images. Furthermore, we provide a scheme for effectively training this model, and include some suggestions for improving performance in terms of efficiency or modeling longer range correlations.
Physics-driven Fire Modeling from Multi-view Images
Apr 14, 2018


Fire effects are widely used in various computer graphics applications such as visual effects and video games. Modeling the shape and appearance of fire phenomenon is challenging as the underlying effects are driven by complex laws of physics. State-of-the-art fire modeling techniques rely on sophisticated physical simulations which require intensive parameter tuning, or use simplifications which produce physically invalid results. In this paper, we present a novel method of reconstructing physically valid fire models from multi-view stereo images. Our method, for the first time, provides plausible estimation of physical properties (e.g., temperature, density) of a fire volume using RGB cameras. This allows for a number of novel phenomena such as global fire illumination effects. The effectiveness and usefulness of our method are tested by generating fire models from a variety of input data, and applying the reconstructed fire models for realistic illumination of virtual scenes.
Structured Uncertainty Prediction Networks
Mar 23, 2018
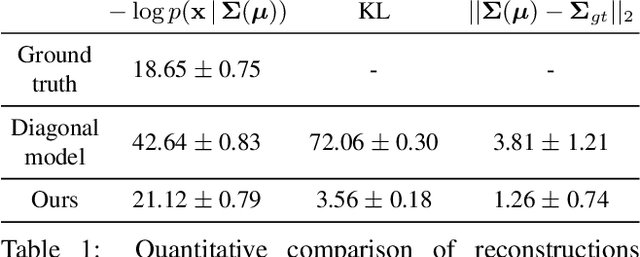
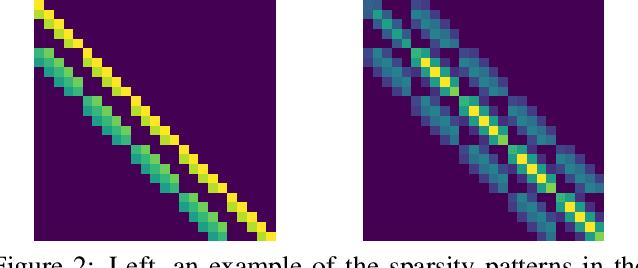

This paper is the first work to propose a network to predict a structured uncertainty distribution for a synthesized image. Previous approaches have been mostly limited to predicting diagonal covariance matrices. Our novel model learns to predict a full Gaussian covariance matrix for each reconstruction, which permits efficient sampling and likelihood evaluation. We demonstrate that our model can accurately reconstruct ground truth correlated residual distributions for synthetic datasets and generate plausible high frequency samples for real face images. We also illustrate the use of these predicted covariances for structure preserving image denoising.