 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Universality-Individuality Integration Model for Dialog Act Classification
Apr 13, 2022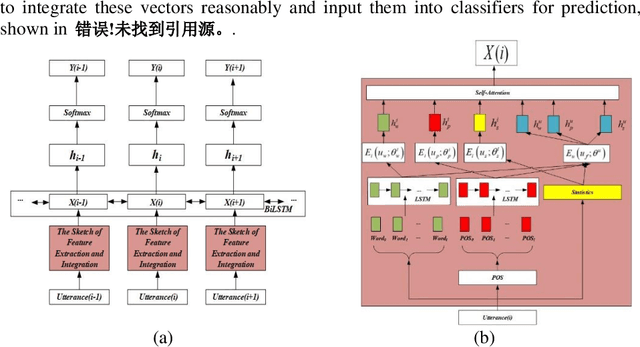

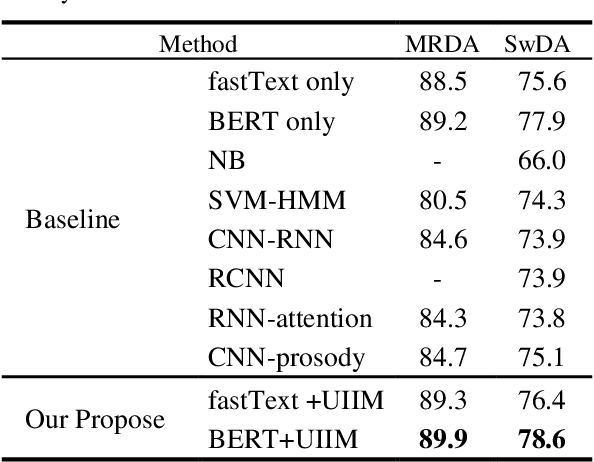
Dialog Act (DA) reveals the general intent of the speaker utterance in a conversation. Accurately predicting DAs can greatly facilitate the development of dialog agents. Although researchers have done extensive research on dialog act classification, the feature information of classification has not been fully considered. This paper suggests that word cues, part-of-speech cues and statistical cues can complement each other to improve the basis for recognition. In addition, the different types of the three lead to the diversity of their distribution forms, which hinders the mining of feature information. To solve this problem, we propose a novel model based on universality and individuality strategies, called Universality-Individuality Integration Model (UIIM). UIIM not only deepens the connection between the clues by learning universality, but also utilizes the learning of individuality to capture the characteristics of the clues themselves. Experiments were made over two most popular benchmark data sets SwDA and MRDA for dialogue act classification, and the results show that extracting the universalities and individualities between cues can more fully excavate the hidden information in the utterance, and improve the accuracy of automatic dialogue act recognition.
A Three-phase Augmented Classifiers Chain Approach Based on Co-occurrence Analysis for Multi-Label Classification
Apr 13, 2022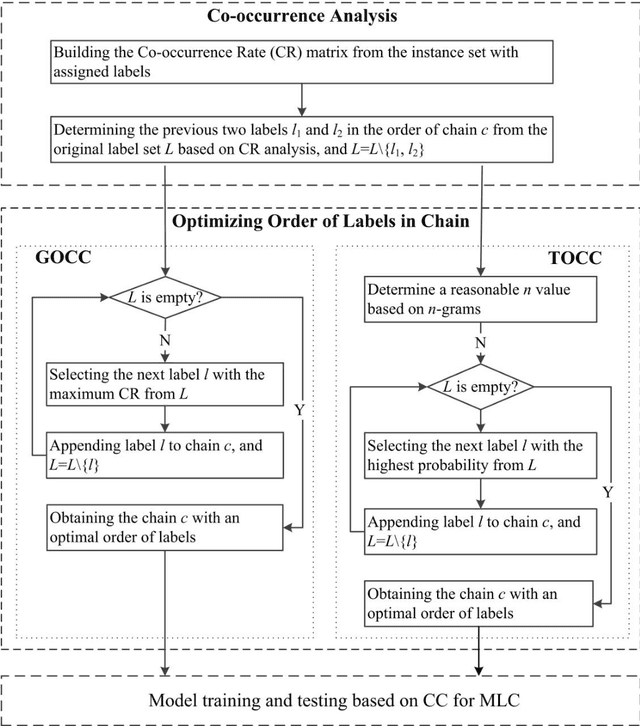
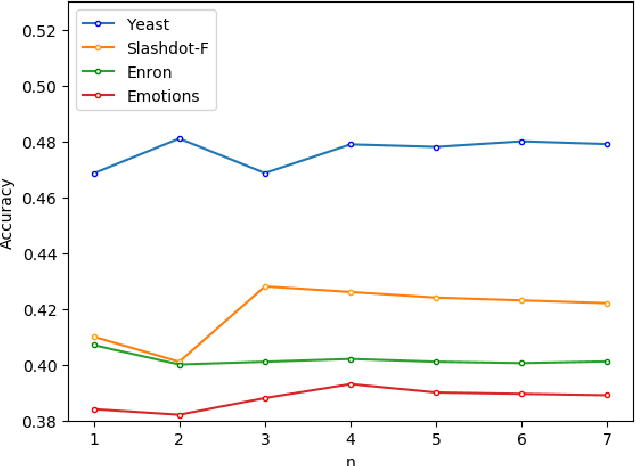
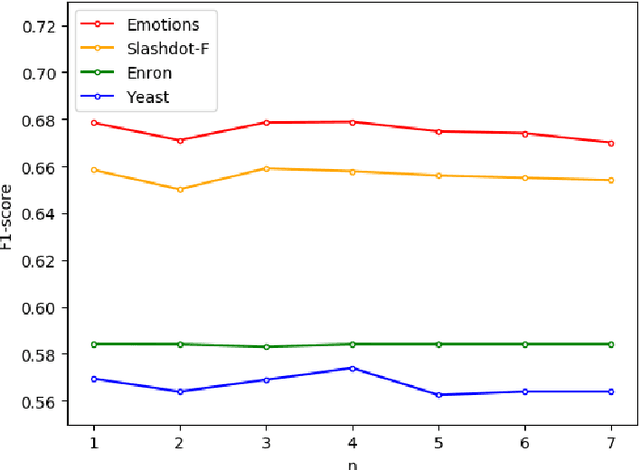
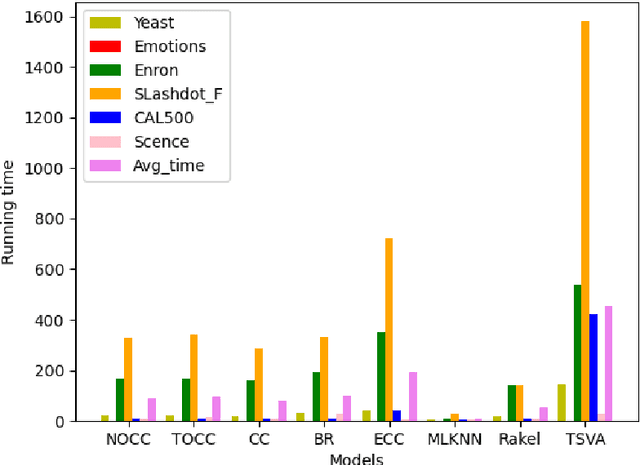
As a very popular multi-label classification method, Classifiers Chain has recently been widely applied to many multi-label classification tasks. However, existing Classifier Chains methods are difficult to model and exploit the underlying dependency in the label space, and often suffer from the problems of poorly ordered chain and error propagation. In this paper, we present a three-phase augmented Classifier Chains approach based on co-occurrence analysis for multi-label classification. First, we propose a co-occurrence matrix method to model the underlying correlations between a label and its precedents and further determine the head labels of a chain. Second, we propose two augmented strategies of optimizing the order of labels of a chain to approximate the underlying label correlations in label space, including Greedy Order Classifier Chain and Trigram Order Classifier Chain. Extensive experiments were made over six benchmark datasets, and the experimental results show that the proposed augmented CC approaches can significantly improve the performance of multi-label classification in comparison with CC and its popular variants of Classifier Chains, in particular maintaining lower computational costs while achieving superior performance.