 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Universality-Individuality Integration Model for Dialog Act Classification
Paper and Code
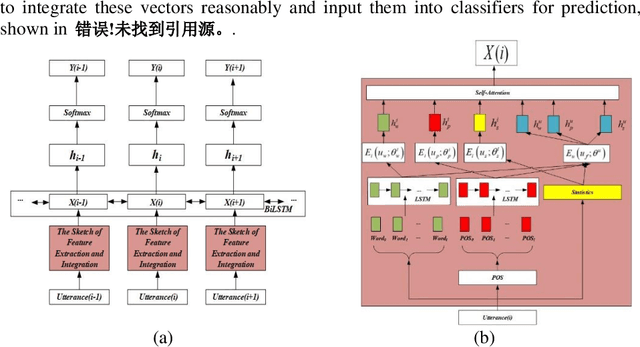

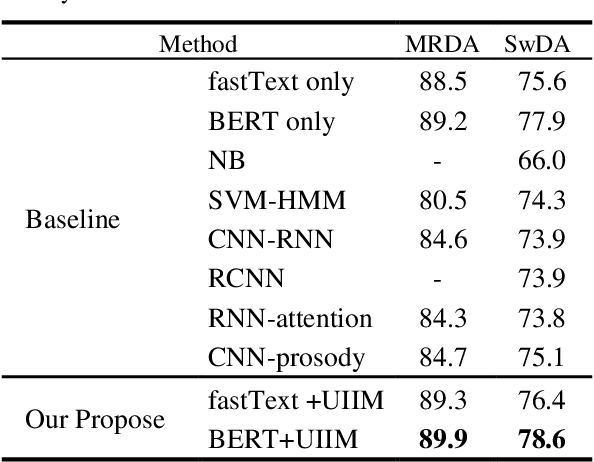
Dialog Act (DA) reveals the general intent of the speaker utterance in a conversation. Accurately predicting DAs can greatly facilitate the development of dialog agents. Although researchers have done extensive research on dialog act classification, the feature information of classification has not been fully considered. This paper suggests that word cues, part-of-speech cues and statistical cues can complement each other to improve the basis for recognition. In addition, the different types of the three lead to the diversity of their distribution forms, which hinders the mining of feature information. To solve this problem, we propose a novel model based on universality and individuality strategies, called Universality-Individuality Integration Model (UIIM). UIIM not only deepens the connection between the clues by learning universality, but also utilizes the learning of individuality to capture the characteristics of the clues themselves. Experiments were made over two most popular benchmark data sets SwDA and MRDA for dialogue act classification, and the results show that extracting the universalities and individualities between cues can more fully excavate the hidden information in the utterance, and improve the accuracy of automatic dialogue act recognition.