 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Target Set Reduction for End-to-End Speech Recognition of Hindi-English Code-Switching Data
Jul 15, 2019
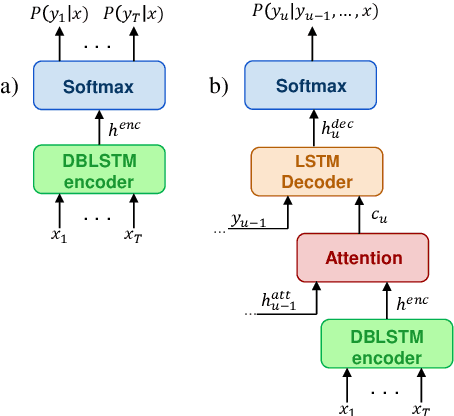

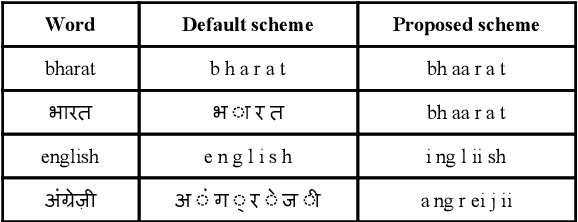
End-to-end (E2E) systems are fast replacing the conventional systems in the domain of automatic speech recognition. As the target labels are learned directly from speech data, the E2E systems need a bigger corpus for effective training. In the context of code-switching task, the E2E systems face two challenges: (i) the expansion of the target set due to multiple languages involved, and (ii) the lack of availability of sufficiently large domain-specific corpus. Towards addressing those challenges, we propose an approach for reducing the number of target labels for reliable training of the E2E systems on limited data. The efficacy of the proposed approach has been demonstrated on two prominent architectures, namely CTC-based and attention-based E2E networks. The experimental validations are performed on a recently created Hindi-English code-switching corpus. For contrast purpose, the results for the full target set based E2E system and a hybrid DNN-HMM system are also reported.
Hindi-English Code-Switching Speech Corpus
Sep 24, 2018



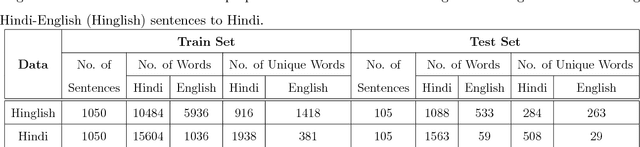
Code-switching refers to the usage of two languages within a sentence or discourse. It is a global phenomenon among multilingual communities and has emerged as an independent area of research. With the increasing demand for the code-switching automatic speech recognition (ASR) systems, the development of a code-switching speech corpus has become highly desirable. However, for training such systems, very limited code-switched resources are available as yet. In this work, we present our first efforts in building a code-switching ASR system in the Indian context. For that purpose, we have created a Hindi-English code-switching speech database. The database not only contains the speech utterances with code-switching properties but also covers the session and the speaker variations like pronunciation, accent, age, gender, etc. This database can be applied in several speech signal processing applications, such as code-switching ASR, language identification, language modeling, speech synthesis etc. This paper mainly presents an analysis of the statistics of the collected code-switching speech corpus. Later, the performance results for the ASR task have been reported for the created database.
Language Modeling for Code-Switched Data: Challenges and Approaches
Nov 09, 2017
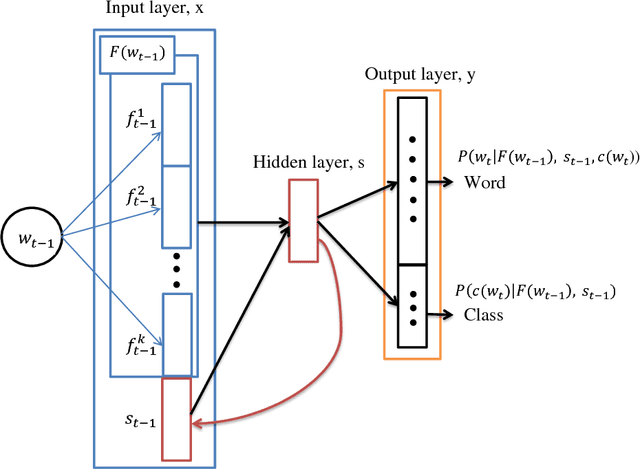

Lately, the problem of code-switching has gained a lot of attention and has emerged as an active area of research. In bilingual communities, the speakers commonly embed the words and phrases of a non-native language into the syntax of a native language in their day-to-day communications. The code-switching is a global phenomenon among multilingual communities, still very limited acoustic and linguistic resources are available as yet. For developing effective speech based applications, the ability of the existing language technologies to deal with the code-switched data can not be over emphasized. The code-switching is broadly classified into two modes: inter-sentential and intra-sentential code-switching. In this work, we have studied the intra-sentential problem in the context of code-switching language modeling task. The salient contributions of this paper includes: (i) the creation of Hindi-English code-switching text corpus by crawling a few blogging sites educating about the usage of the Internet (ii) the exploration of the parts-of-speech features towards more effective modeling of Hindi-English code-switched data by the monolingual language model (LM) trained on native (Hindi) language data, and (iii) the proposal of a novel textual factor referred to as the code-switch factor (CS-factor), which allows the LM to predict the code-switching instances. In the context of recognition of the code-switching data, the substantial reduction in the PPL is achieved with the use of POS factors and also the proposed CS-factor provides independent as well as additive gain in the PPL.