 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Target Set Reduction for End-to-End Speech Recognition of Hindi-English Code-Switching Data
Paper and Code
Jul 15, 2019
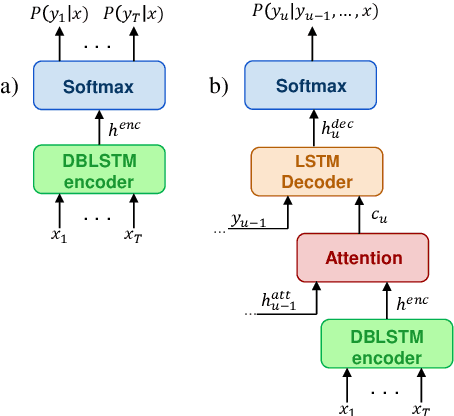

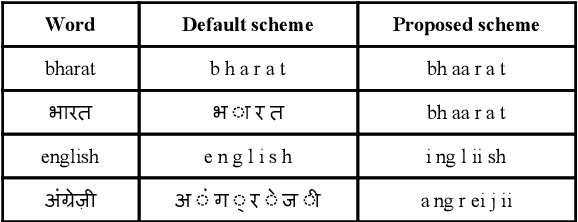
End-to-end (E2E) systems are fast replacing the conventional systems in the domain of automatic speech recognition. As the target labels are learned directly from speech data, the E2E systems need a bigger corpus for effective training. In the context of code-switching task, the E2E systems face two challenges: (i) the expansion of the target set due to multiple languages involved, and (ii) the lack of availability of sufficiently large domain-specific corpus. Towards addressing those challenges, we propose an approach for reducing the number of target labels for reliable training of the E2E systems on limited data. The efficacy of the proposed approach has been demonstrated on two prominent architectures, namely CTC-based and attention-based E2E networks. The experimental validations are performed on a recently created Hindi-English code-switching corpus. For contrast purpose, the results for the full target set based E2E system and a hybrid DNN-HMM system are also reported.