 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Momentum and Nonlinear Damping for Neural Network Training
Jan 30, 2026We propose a continuous-time scheme for large-scale optimization that introduces individual, adaptive momentum coefficients regulated by the kinetic energy of each model parameter. This approach automatically adjusts to local landscape curvature to maintain stability without sacrificing convergence speed. We demonstrate that our adaptive friction can be related to cubic damping, a suppression mechanism from structural dynamics. Furthermore, we introduce two specific optimization schemes by augmenting the continuous dynamics of mSGD and Adam with a cubic damping term. Empirically, our methods demonstrate robustness and match or outperform Adam on training ViT, BERT, and GPT2 tasks where mSGD typically struggles. We further provide theoretical results establishing the exponential convergence of the proposed schemes.
Generative modeling of conditional probability distributions on the level-sets of collective variables
Dec 22, 2025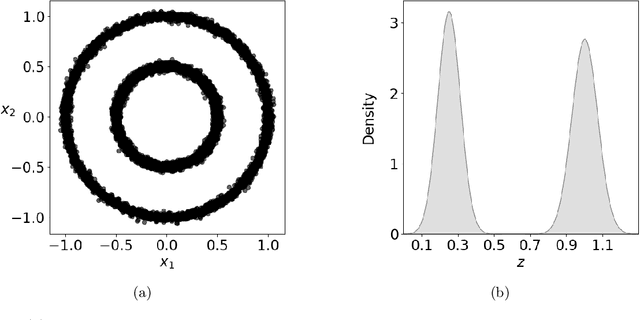
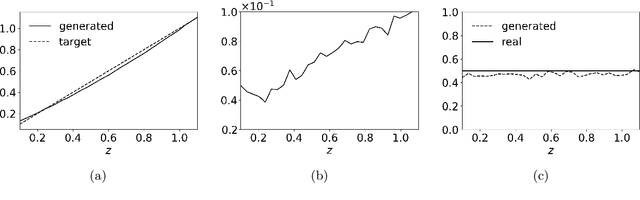

Given a probability distribution $μ$ in $\mathbb{R}^d$ represented by data, we study in this paper the generative modeling of its conditional probability distributions on the level-sets of a collective variable $ξ: \mathbb{R}^d \rightarrow \mathbb{R}^k$, where $1 \le k<d$. We propose a general and efficient learning approach that is able to learn generative models on different level-sets of $ξ$ simultaneously. To improve the learning quality on level-sets in low-probability regions, we also propose a strategy for data enrichment by utilizing data from enhanced sampling techniques. We demonstrate the effectiveness of our proposed learning approach through concrete numerical examples. The proposed approach is potentially useful for the generative modeling of molecular systems in biophysics, for instance.
Generative methods for sampling transition paths in molecular dynamics
May 05, 2022



Molecular systems often remain trapped for long times around some local minimum of the potential energy function, before switching to another one -- a behavior known as metastability. Simulating transition paths linking one metastable state to another one is difficult by direct numerical methods. In view of the promises of machine learning techniques, we explore in this work two approaches to more efficiently generate transition paths: sampling methods based on generative models such as variational autoencoders, and importance sampling methods based on reinforcement learning.
Removing the mini-batching error in Bayesian inference using Adaptive Langevin dynamics
May 21, 2021



The computational cost of usual Monte Carlo methods for sampling a posteriori laws in Bayesian inference scales linearly with the number of data points. One option to reduce it to a fraction of this cost is to resort to mini-batching in conjunction with unadjusted discretizations of Langevin dynamics, in which case only a random fraction of the data is used to estimate the gradient. However, this leads to an additional noise in the dynamics and hence a bias on the invariant measure which is sampled by the Markov chain. We advocate using the so-called Adaptive Langevin dynamics, which is a modification of standard inertial Langevin dynamics with a dynamical friction which automatically corrects for the increased noise arising from mini-batching. We investigate the practical relevance of the assumptions underpinning Adaptive Langevin (constant covariance for the estimation of the gradient), which are not satisfied in typical models of Bayesian inference; and show how to extend the approach to more general situations.
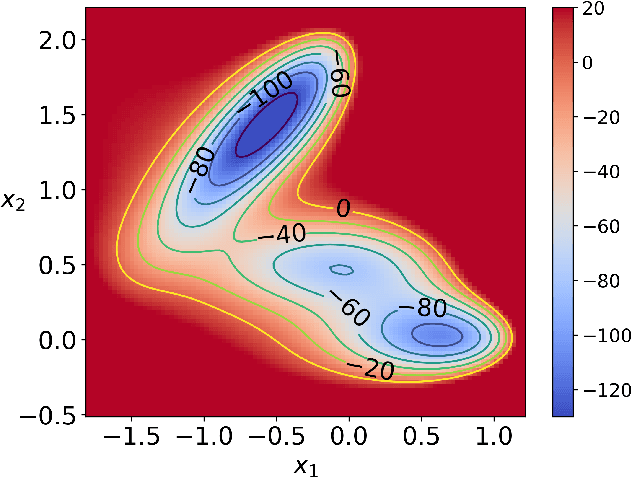
Chasing Collective Variables using Autoencoders and biased trajectories
Apr 22, 2021



In the last decades, free energy biasing methods have proven to be powerful tools to accelerate the simulation of important conformational changes of molecules by modifying the sampling measure. However, most of these methods rely on the prior knowledge of low-dimensional slow degrees of freedom, i.e. Collective Variables (CV). Alternatively, such CVs can be identified using machine learning (ML) and dimensionality reduction algorithms. In this context, approaches where the CVs are learned in an iterative way using adaptive biasing have been proposed: at each iteration, the learned CV is used to perform free energy adaptive biasing to generate new data and learn a new CV. This implies that at each iteration, a different measure is sampled, thus the new training data is distributed according to a different distribution. Given that a machine learning model is always dependent on the considered distribution, iterative methods are not guaranteed to converge to a certain CV. This can be remedied by a reweighting procedure to always fall back to learning with respect to the same unbiased Boltzmann-Gibbs measure, regardless of the biased measure used in the adaptive sampling. In this paper, we introduce a new iterative method involving CV learning with autoencoders: Free Energy Biasing and Iterative Learning with AutoEncoders (FEBILAE). Our method includes the reweighting scheme to ensure that the learning model optimizes the same loss, and achieves CV convergence. Using a small 2-dimensional toy system and the alanine dipeptide system as examples, we present results of our algorithm using the extended adaptive biasing force as the free energy adaptive biasing method.