 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision Making Agent Searching for Markov Models in Near-Deterministic World
Mar 01, 2011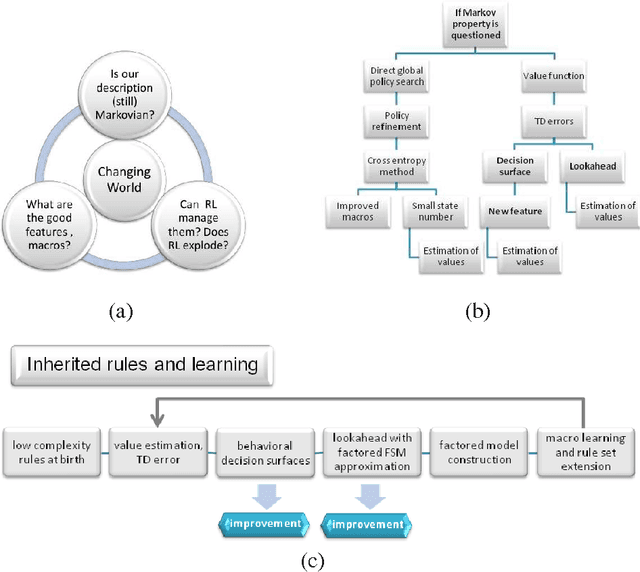
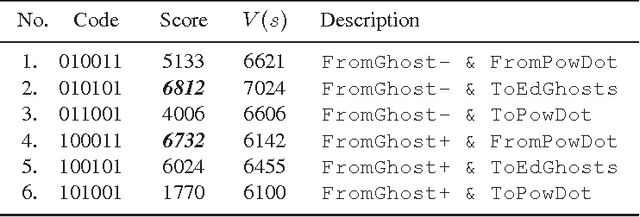


Reinforcement learning has solid foundations, but becomes inefficient in partially observed (non-Markovian) environments. Thus, a learning agent -born with a representation and a policy- might wish to investigate to what extent the Markov property holds. We propose a learning architecture that utilizes combinatorial policy optimization to overcome non-Markovity and to develop efficient behaviors, which are easy to inherit, tests the Markov property of the behavioral states, and corrects against non-Markovity by running a deterministic factored Finite State Model, which can be learned. We illustrate the properties of architecture in the near deterministic Ms. Pac-Man game. We analyze the architecture from the point of view of evolutionary, individual, and social learning.