 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset of Quotation Attribution in German News Articles
Apr 25, 2024
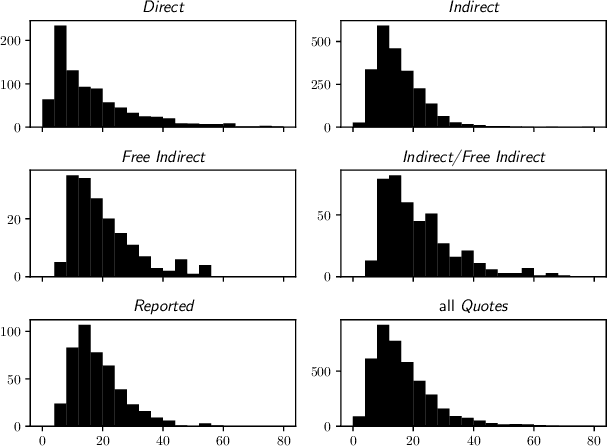

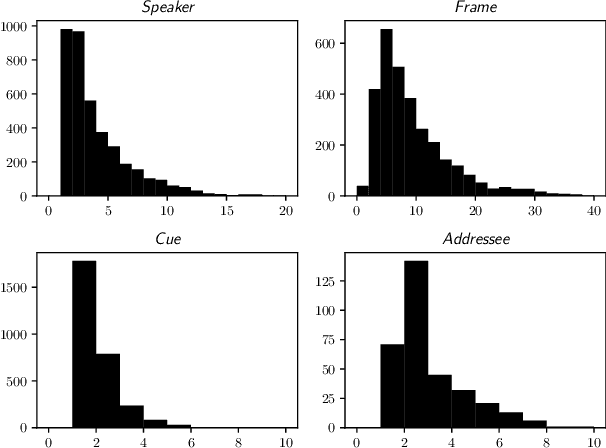
Extracting who says what to whom is a crucial part in analyzing human communication in today's abundance of data such as online news articles. Yet, the lack of annotated data for this task in German news articles severely limits the quality and usability of possible systems. To remedy this, we present a new, freely available, creative-commons-licensed dataset for quotation attribution in German news articles based on WIKINEWS. The dataset provides curated, high-quality annotations across 1000 documents (250,000 tokens) in a fine-grained annotation schema enabling various downstream uses for the dataset. The annotations not only specify who said what but also how, in which context, to whom and define the type of quotation. We specify our annotation schema, describe the creation of the dataset and provide a quantitative analysis. Further, we describe suitable evaluation metrics, apply two existing systems for quotation attribution, discuss their results to evaluate the utility of our dataset and outline use cases of our dataset in downstream tasks.