 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Task Belief Similarity with Latent Dynamics for Meta-Reinforcement Learning
Jun 24, 2025Meta-reinforcement learning requires utilizing prior task distribution information obtained during exploration to rapidly adapt to unknown tasks. The efficiency of an agent's exploration hinges on accurately identifying the current task. Recent Bayes-Adaptive Deep RL approaches often rely on reconstructing the environment's reward signal, which is challenging in sparse reward settings, leading to suboptimal exploitation. Inspired by bisimulation metrics, which robustly extracts behavioral similarity in continuous MDPs, we propose SimBelief-a novel meta-RL framework via measuring similarity of task belief in Bayes-Adaptive MDP (BAMDP). SimBelief effectively extracts common features of similar task distributions, enabling efficient task identification and exploration in sparse reward environments. We introduce latent task belief metric to learn the common structure of similar tasks and incorporate it into the specific task belief. By learning the latent dynamics across task distributions, we connect shared latent task belief features with specific task features, facilitating rapid task identification and adaptation. Our method outperforms state-of-the-art baselines on sparse reward MuJoCo and panda-gym tasks.
Memory Sequence Length of Data Sampling Impacts the Adaptation of Meta-Reinforcement Learning Agents
Jun 18, 2024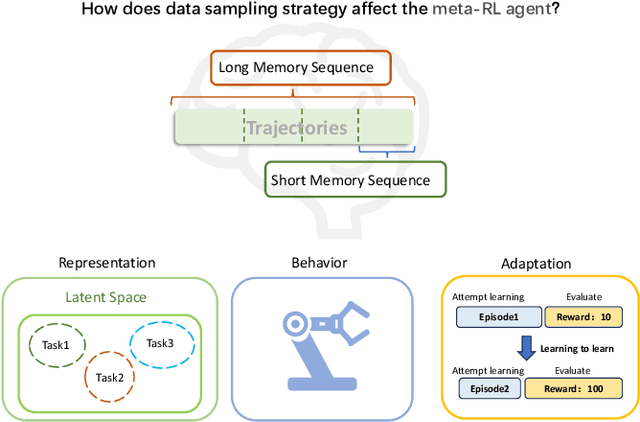
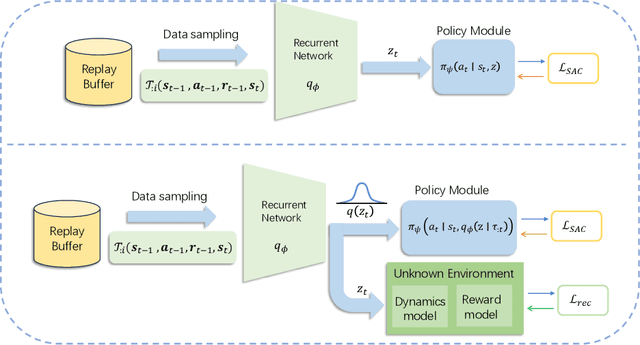


Fast adaptation to new tasks is extremely important for embodied agents in the real world. Meta-reinforcement learning (meta-RL) has emerged as an effective method to enable fast adaptation in unknown environments. Compared to on-policy meta-RL algorithms, off-policy algorithms rely heavily on efficient data sampling strategies to extract and represent the historical trajectories. However, little is known about how different data sampling methods impact the ability of meta-RL agents to represent unknown environments. Here, we investigate the impact of data sampling strategies on the exploration and adaptability of meta-RL agents. Specifically, we conducted experiments with two types of off-policy meta-RL algorithms based on Thompson sampling and Bayes-optimality theories in continuous control tasks within the MuJoCo environment and sparse reward navigation tasks. Our analysis revealed the long-memory and short-memory sequence sampling strategies affect the representation and adaptive capabilities of meta-RL agents. We found that the algorithm based on Bayes-optimality theory exhibited more robust and better adaptability than the algorithm based on Thompson sampling, highlighting the importance of appropriate data sampling strategies for the agent's representation of an unknown environment, especially in the case of sparse rewards.