 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUTEv2: Unified and Configurable Matrix Extension for Diverse CPU Architectures with Minimal Design Overhead
Apr 13, 2026Matrix extensions have emerged as an essential feature in modern CPUs to address the surging demands of AI workloads. However, existing designs often incur substantial hardware and software design overhead. Tight coupling with the CPU pipeline complicates integration across diverse CPUs, while fine-grained synchronous instructions hinder the development of high-performance kernels. This paper proposes a unified and configurable CPU matrix extension architecture. By decoupling matrix units from the CPU pipeline, the design enables low-overhead integration while maintaining close coordination with existing compute and memory resources. The configurable matrix unit supports mixed-precision operations and adapts to diverse compute demands and memory bandwidth constraints. An asynchronous matrix multiplication abstraction with flexible granularity conceals hardware details, simplifies matrix-vector overlap, and supports a unified software stack. The architecture is integrated into four open-source CPU RTL platforms and evaluated on representative AI models. Matrix unit utilization under GEMM workloads exceeds 90% across all platforms. When configured with compute throughput and memory bandwidth comparable to Intel AMX, our design achieves speedups of 1.57x, 1.57x, and 2.31x on ResNet, BERT, and Llama3, with over 30% of the gains attributed to overlapped matrix-vector execution. A 4 TOPS@2GHz matrix unit occupies only 0.53 mm\textsuperscript{2} in 14nm CMOS. These results demonstrate strong cross-platform adaptability and effective hardware-software co-optimization, offering a practical matrix extension for the open-source community.
Deep Learning Based Automatic Modulation Recognition: Models, Datasets, and Challenges
Jul 20, 2022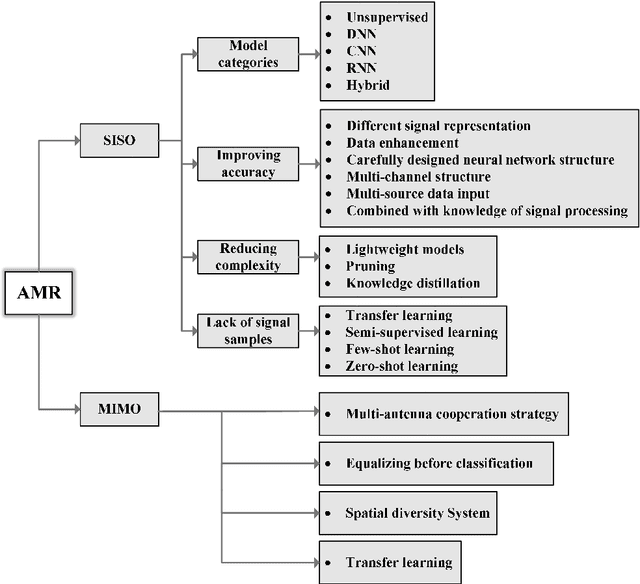
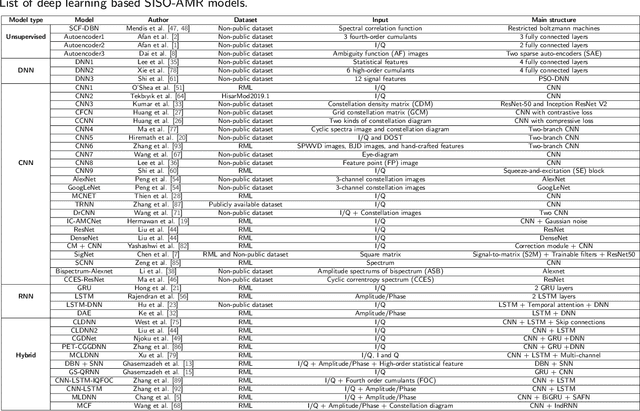
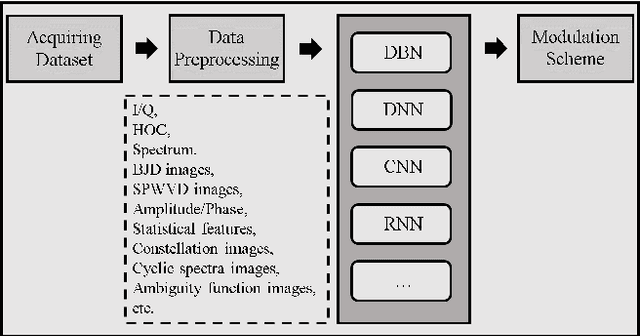
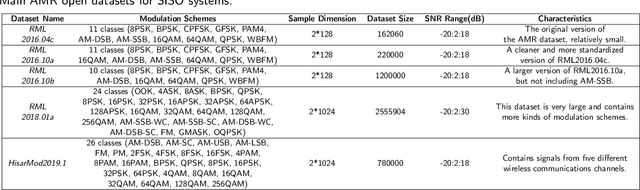
Automatic modulation recognition (AMR) detects the modulation scheme of the received signals for further signal processing without needing prior information, and provides the essential function when such information is missing. Recent breakthroughs in deep learning (DL) have laid the foundation for developing high-performance DL-AMR approaches for communications systems. Comparing with traditional modulation detection methods, DL-AMR approaches have achieved promising performance including high recognition accuracy and low false alarms due to the strong feature extraction and classification abilities of deep neural networks. Despite the promising potential, DL-AMR approaches also bring concerns to complexity and explainability, which affect the practical deployment in wireless communications systems. This paper aims to present a review of the current DL-AMR research, with a focus on appropriate DL models and benchmark datasets. We further provide comprehensive experiments to compare the state of the art models for single-input-single-output (SISO) systems from both accuracy and complexity perspectives, and propose to apply DL-AMR in the new multiple-input-multiple-output (MIMO) scenario with precoding. Finally, existing challenges and possible future research directions are discussed.
An Efficient Deep Learning Model for Automatic Modulation Recognition Based on Parameter Estimation and Transformation
Oct 11, 2021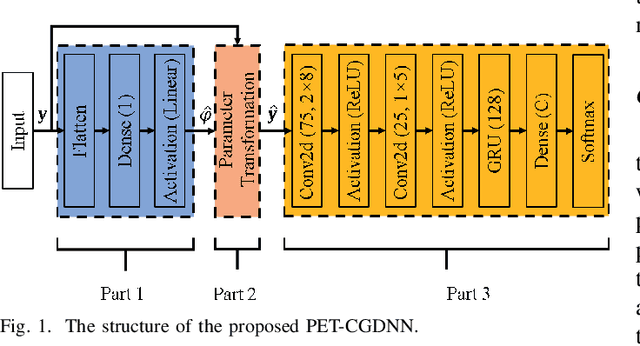
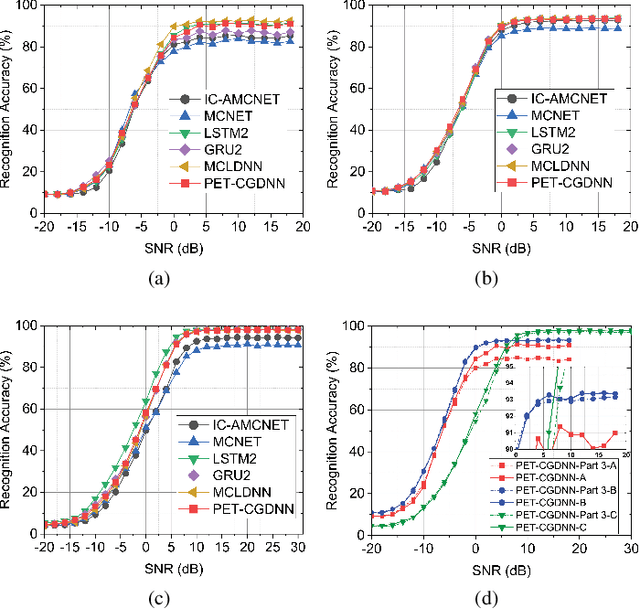
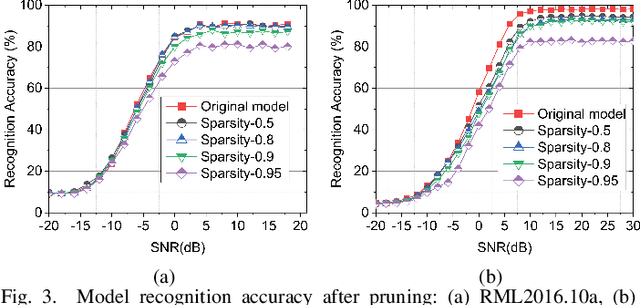
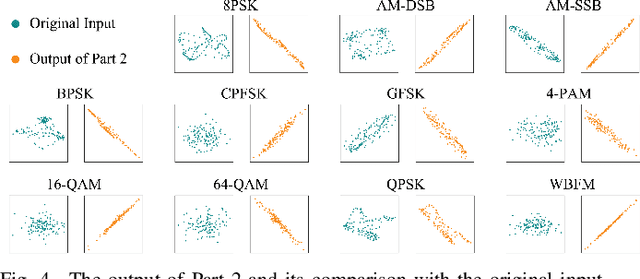
Automatic modulation recognition (AMR) is a promising technology for intelligent communication receivers to detect signal modulation schemes. Recently, the emerging deep learning (DL) research has facilitated high-performance DL-AMR approaches. However, most DL-AMR models only focus on recognition accuracy, leading to huge model sizes and high computational complexity, while some lightweight and low-complexity models struggle to meet the accuracy requirements. This letter proposes an efficient DL-AMR model based on phase parameter estimation and transformation, with convolutional neural network (CNN) and gated recurrent unit (GRU) as the feature extraction layers, which can achieve high recognition accuracy equivalent to the existing state-of-the-art models but reduces more than a third of the volume of their parameters. Meanwhile, our model is more competitive in training time and test time than the benchmark models with similar recognition accuracy. Moreover, we further propose to compress our model by pruning, which maintains the recognition accuracy higher than 90% while has less than 1/8 of the number of parameters comparing with state-of-the-art models.