Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Deep Neural Network for Speaker and Language Recognition
Apr 03, 2015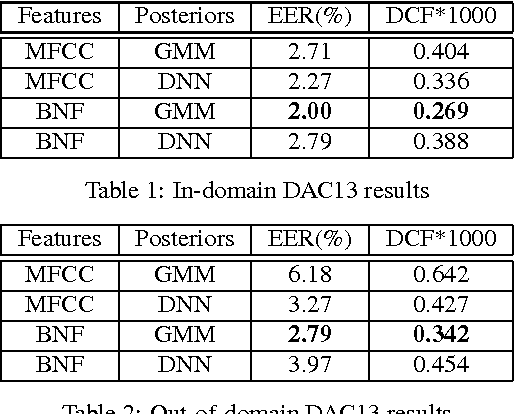
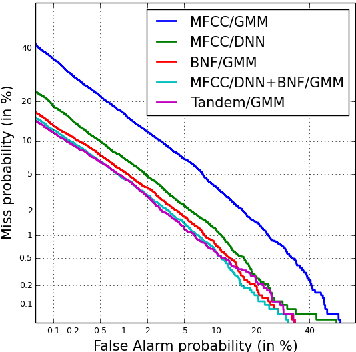
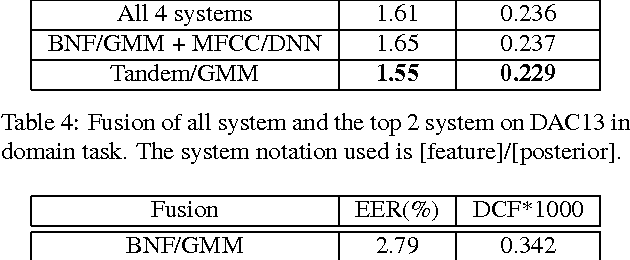
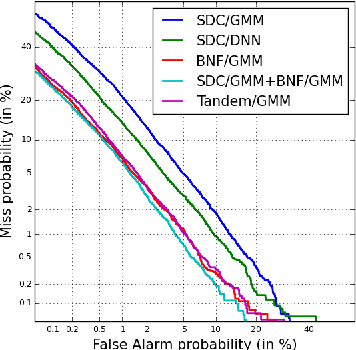
Learned feature representations and sub-phoneme posteriors from Deep Neural Networks (DNNs) have been used separately to produce significant performance gains for speaker and language recognition tasks. In this work we show how these gains are possible using a single DNN for both speaker and language recognition. The unified DNN approach is shown to yield substantial performance improvements on the the 2013 Domain Adaptation Challenge speaker recognition task (55% reduction in EER for the out-of-domain condition) and on the NIST 2011 Language Recognition Evaluation (48% reduction in EER for the 30s test condition).
Via