 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinding Dancers Into Attractors
Jun 01, 2022
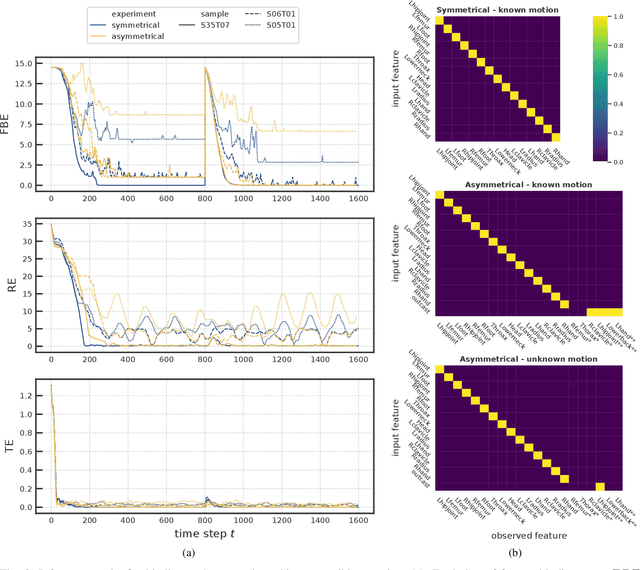
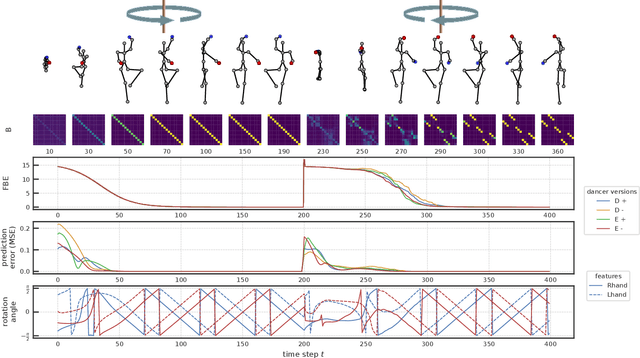

To effectively perceive and process observations in our environment, feature binding and perspective taking are crucial cognitive abilities. Feature binding combines observed features into one entity, called a Gestalt. Perspective taking transfers the percept into a canonical, observer-centered frame of reference. Here we propose a recurrent neural network model that solves both challenges. We first train an LSTM to predict 3D motion dynamics from a canonical perspective. We then present similar motion dynamics with novel viewpoints and feature arrangements. Retrospective inference enables the deduction of the canonical perspective. Combined with a robust mutual-exclusive softmax selection scheme, random feature arrangements are reordered and precisely bound into known Gestalt percepts. To corroborate evidence for the architecture's cognitive validity, we examine its behavior on the silhouette illusion, which elicits two competitive Gestalt interpretations of a rotating dancer. Our system flexibly binds the information of the rotating figure into the alternative attractors resolving the illusion's ambiguity and imagining the respective depth interpretation and the corresponding direction of rotation. We finally discuss the potential universality of the proposed mechanisms.