 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA-Muon: Spectral Steepest Descent on the Low-Rank Manifold
Jun 11, 2026Low-Rank Adaptation (LoRA) significantly reduces compute and memory costs for finetuning Deep Learning models but is often harder to tune than dense training: when using factor-wise optimizers such as AdamW, it is sensitive to initialization choices, its optimal learning rates transfer poorly across ranks, and it often fails to beat dense baselines. We derive LoRA-Muon by applying the Muon optimizer's spectral steepest-descent rule to the low-rank setting. Along with our split weight-decay rule, our main claim is that LoRA-Muon is a good low-rank proxy for full-rank Muon and Shampoo-family optimizers. Its optimal learning rates transfer across rank, width, depth, and factor-rescaling. In our compute-matched TinyShakespeare study, a rank-$2$ proxy recovers the dense best tested learning rate, and a rank-$32$ LoRA-Muon run attains lower mean validation loss than the dense baseline in the seed-averaged sweep. We further show that the Spectron optimizer depends on arbitrary factor scaling, so it would likely be a poor fit when finetuning starts from badly imbalanced factors, and that LoRA-RITE's simplified QR-coordinate core implements the same spectral update. LoRA-Muon computes that update without QR-decomposition and avoids storing second moments, making it more accelerator-friendly and memory-efficient.
Multimodal Structured Generation: CVPR's 2nd MMFM Challenge Technical Report
Jun 17, 2024Multimodal Foundation Models (MMFMs) have shown remarkable performance on various computer vision and natural language processing tasks. However, their performance on particular tasks such as document understanding is still limited. They also require more compute, time, and engineering resources to finetune and deploy compared to traditional, unimodal models. In this report, we present Multimodal Structured Generation, a general framework which constrains the output logits of frozen MMFMs to force them to reason before responding with structured outputs that downstream APIs can parse and use. We provide a detailed account of our approach, including the technical details, theoretical discussions, and final evaluation results in the 2nd Multimodal Foundation Models Challenge hosted by the Computer Vision and Pattern Recognition (CVPR) conference. Our approach achieved the second highest score in the hidden test set for Phase 2 and third highest overall. This shows the method's ability to generalize to unseen tasks. And that simple engineering can beat expensive & complicated modelling steps as we first discussed in our paper, Retrieval Augmented Structured Generation: Business Document Information Extraction as Tool Use. All of our scripts, deployment steps, and evaluation results can be accessed in https://github.com/leloykun/MMFM-Challenge
Retrieval Augmented Structured Generation: Business Document Information Extraction As Tool Use
May 30, 2024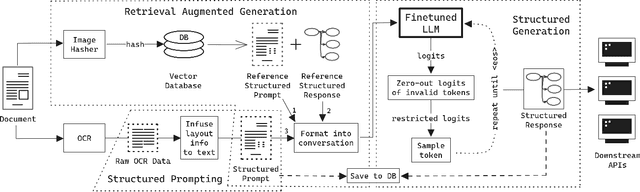


Business Document Information Extraction (BDIE) is the problem of transforming a blob of unstructured information (raw text, scanned documents, etc.) into a structured format that downstream systems can parse and use. It has two main tasks: Key-Information Extraction (KIE) and Line Items Recognition (LIR). In this paper, we argue that BDIE is best modeled as a Tool Use problem, where the tools are these downstream systems. We then present Retrieval Augmented Structured Generation (RASG), a novel general framework for BDIE that achieves state of the art (SOTA) results on both KIE and LIR tasks on BDIE benchmarks. The contributions of this paper are threefold: (1) We show, with ablation benchmarks, that Large Language Models (LLMs) with RASG are already competitive with or surpasses current SOTA Large Multimodal Models (LMMs) without RASG on BDIE benchmarks. (2) We propose a new metric class for Line Items Recognition, General Line Items Recognition Metric (GLIRM), that is more aligned with practical BDIE use cases compared to existing metrics, such as ANLS*, DocILE, and GriTS. (3) We provide a heuristic algorithm for backcalculating bounding boxes of predicted line items and tables without the need for vision encoders. Finally, we claim that, while LMMs might sometimes offer marginal performance benefits, LLMs + RASG is oftentimes superior given real-world applications and constraints of BDIE.