 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeed for Design Patterns: Interoperability Issues and Modelling Challenges for Observational Data
Aug 26, 2022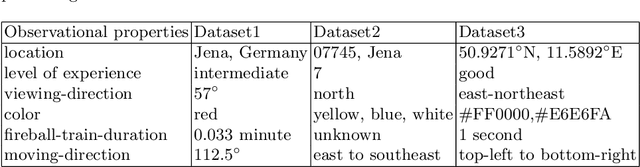

Interoperability issues concerning observational data have gained attention in recent times. Automated data integration is important when it comes to the scientific analysis of observational data from different sources. However, it is hampered by various data interoperability issues. We focus exclusively on semantic interoperability issues for observational characteristics. We propose a use-case-driven approach to identify general classes of interoperability issues. In this paper, this is exemplarily done for the use-case of citizen science fireball observations. We derive key concepts for the identified interoperability issues that are generalizable to observational data in other fields of science. These key concepts contain several modeling challenges, and we broadly describe each modeling challenges associated with its interoperability issue. We believe, that addressing these challenges with a set of ontology design patterns will be an effective means for unified semantic modeling, paving the way for a unified approach for resolving interoperability issues in observational data. We demonstrate this with one design pattern, highlighting the importance and need for ontology design patterns for observational data, and leave the remaining patterns to future work. Our paper thus describes interoperability issues along with modeling challenges as a starting point for developing a set of extensible and reusable design patterns.
Machine Learning Pipelines: Provenance, Reproducibility and FAIR Data Principles
Jun 22, 2020Machine learning (ML) is an increasingly important scientific tool supporting decision making and knowledge generation in numerous fields. With this, it also becomes more and more important that the results of ML experiments are reproducible. Unfortunately, that often is not the case. Rather, ML, similar to many other disciplines, faces a reproducibility crisis. In this paper, we describe our goals and initial steps in supporting the end-to-end reproducibility of ML pipelines. We investigate which factors beyond the availability of source code and datasets influence reproducibility of ML experiments. We propose ways to apply FAIR data practices to ML workflows. We present our preliminary results on the role of our tool, ProvBook, in capturing and comparing provenance of ML experiments and their reproducibility using Jupyter Notebooks.