 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Explanations or Random Noise? A Reliability Metric for XAI
Feb 04, 2026In recent years, explaining decisions made by complex machine learning models has become essential in high-stakes domains such as energy systems, healthcare, finance, and autonomous systems. However, the reliability of these explanations, namely, whether they remain stable and consistent under realistic, non-adversarial changes, remains largely unmeasured. Widely used methods such as SHAP and Integrated Gradients (IG) are well-motivated by axiomatic notions of attribution, yet their explanations can vary substantially even under system-level conditions, including small input perturbations, correlated representations, and minor model updates. Such variability undermines explanation reliability, as reliable explanations should remain consistent across equivalent input representations and small, performance-preserving model changes. We introduce the Explanation Reliability Index (ERI), a family of metrics that quantifies explanation stability under four reliability axioms: robustness to small input perturbations, consistency under feature redundancy, smoothness across model evolution, and resilience to mild distributional shifts. For each axiom, we derive formal guarantees, including Lipschitz-type bounds and temporal stability results. We further propose ERI-T, a dedicated measure of temporal reliability for sequential models, and introduce ERI-Bench, a benchmark designed to systematically stress-test explanation reliability across synthetic and real-world datasets. Experimental results reveal widespread reliability failures in popular explanation methods, showing that explanations can be unstable under realistic deployment conditions. By exposing and quantifying these instabilities, ERI enables principled assessment of explanation reliability and supports more trustworthy explainable AI (XAI) systems.
Adaptive Quantum-Safe Cryptography for 6G Vehicular Networks via Context-Aware Optimization
Feb 01, 2026Powerful quantum computers in the future may be able to break the security used for communication between vehicles and other devices (Vehicle-to-Everything, or V2X). New security methods called post-quantum cryptography can help protect these systems, but they often require more computing power and can slow down communication, posing a challenge for fast 6G vehicle networks. In this paper, we propose an adaptive post-quantum cryptography (PQC) framework that predicts short-term mobility and channel variations and dynamically selects suitable lattice-, code-, or hash-based PQC configurations using a predictive multi-objective evolutionary algorithm (APMOEA) to meet vehicular latency and security constraints.However, frequent cryptographic reconfiguration in dynamic vehicular environments introduces new attack surfaces during algorithm transitions. A secure monotonic-upgrade protocol prevents downgrade, replay, and desynchronization attacks during transitions. Theoretical results show decision stability under bounded prediction error, latency boundedness under mobility drift, and correctness under small forecast noise. These results demonstrate a practical path toward quantum-safe cryptography in future 6G vehicular networks. Through extensive experiments based on realistic mobility (LuST), weather (ERA5), and NR-V2X channel traces, we show that the proposed framework reduces end-to-end latency by up to 27\%, lowers communication overhead by up to 65\%, and effectively stabilizes cryptographic switching behavior using reinforcement learning. Moreover, under the evaluated adversarial scenarios, the monotonic-upgrade protocol successfully prevents downgrade, replay, and desynchronization attacks.
Context Dependence and Reliability in Autoregressive Language Models
Feb 01, 2026Large language models (LLMs) generate outputs by utilizing extensive context, which often includes redundant information from prompts, retrieved passages, and interaction history. In critical applications, it is vital to identify which context elements actually influence the output, as standard explanation methods struggle with redundancy and overlapping context. Minor changes in input can lead to unpredictable shifts in attribution scores, undermining interpretability and raising concerns about risks like prompt injection. This work addresses the challenge of distinguishing essential context elements from correlated ones. We introduce RISE (Redundancy-Insensitive Scoring of Explanation), a method that quantifies the unique influence of each input relative to others, minimizing the impact of redundancies and providing clearer, stable attributions. Experiments demonstrate that RISE offers more robust explanations than traditional methods, emphasizing the importance of conditional information for trustworthy LLM explanations and monitoring.
Explainability of Complex AI Models with Correlation Impact Ratio
Jan 10, 2026Complex AI systems make better predictions but often lack transparency, limiting trustworthiness, interpretability, and safe deployment. Common post hoc AI explainers, such as LIME, SHAP, HSIC, and SAGE, are model agnostic but are too restricted in one significant regard: they tend to misrank correlated features and require costly perturbations, which do not scale to high dimensional data. We introduce ExCIR (Explainability through Correlation Impact Ratio), a theoretically grounded, simple, and reliable metric for explaining the contribution of input features to model outputs, which remains stable and consistent under noise and sampling variations. We demonstrate that ExCIR captures dependencies arising from correlated features through a lightweight single pass formulation. Experimental evaluations on diverse datasets, including EEG, synthetic vehicular data, Digits, and Cats-Dogs, validate the effectiveness and stability of ExCIR across domains, achieving more interpretable feature explanations than existing methods while remaining computationally efficient. To this end, we further extend ExCIR with an information theoretic foundation that unifies the correlation ratio with Canonical Correlation Analysis under mutual information bounds, enabling multi output and class conditioned explainability at scale.
Combinatorial Auctions and Graph Neural Networks for Local Energy Flexibility Markets
Jul 25, 2023



This paper proposes a new combinatorial auction framework for local energy flexibility markets, which addresses the issue of prosumers' inability to bundle multiple flexibility time intervals. To solve the underlying NP-complete winner determination problems, we present a simple yet powerful heterogeneous tri-partite graph representation and design graph neural network-based models. Our models achieve an average optimal value deviation of less than 5\% from an off-the-shelf optimization tool and show linear inference time complexity compared to the exponential complexity of the commercial solver. Contributions and results demonstrate the potential of using machine learning to efficiently allocate energy flexibility resources in local markets and solving optimization problems in general.
Balancing Explainability-Accuracy of Complex Models
May 23, 2023Explainability of AI models is an important topic that can have a significant impact in all domains and applications from autonomous driving to healthcare. The existing approaches to explainable AI (XAI) are mainly limited to simple machine learning algorithms, and the research regarding the explainability-accuracy tradeoff is still in its infancy especially when we are concerned about complex machine learning techniques like neural networks and deep learning (DL). In this work, we introduce a new approach for complex models based on the co-relation impact which enhances the explainability considerably while also ensuring the accuracy at a high level. We propose approaches for both scenarios of independent features and dependent features. In addition, we study the uncertainty associated with features and output. Furthermore, we provide an upper bound of the computation complexity of our proposed approach for the dependent features. The complexity bound depends on the order of logarithmic of the number of observations which provides a reliable result considering the higher dimension of dependent feature space with a smaller number of observations.
Distributed Deep Reinforcement Learning for Intelligent Load Scheduling in Residential Smart Grids
Jun 29, 2020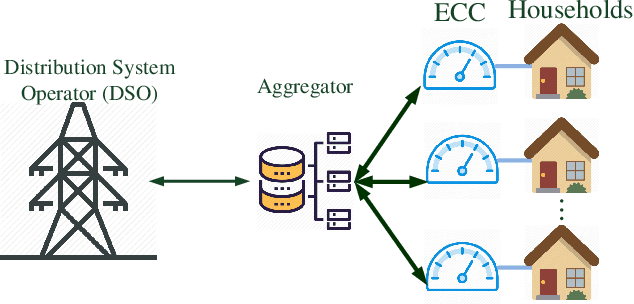
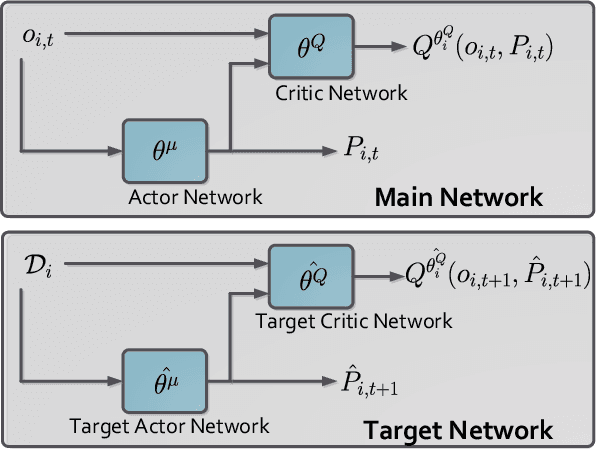
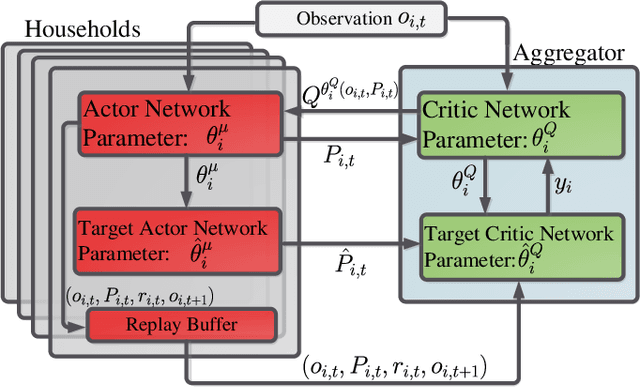
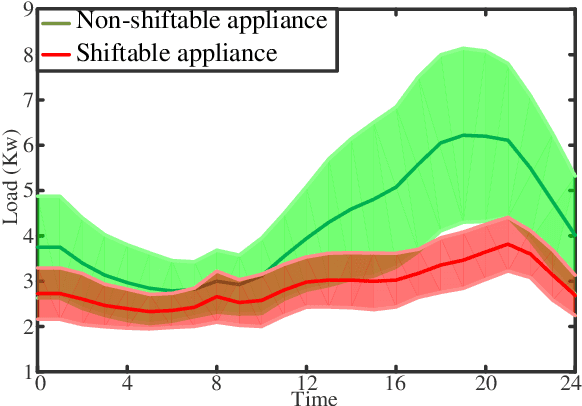
The power consumption of households has been constantly growing over the years. To cope with this growth, intelligent management of the consumption profile of the households is necessary, such that the households can save the electricity bills, and the stress to the power grid during peak hours can be reduced. However, implementing such a method is challenging due to the existence of randomness in the electricity price and the consumption of the appliances. To address this challenge, we employ a model-free method for the households which works with limited information about the uncertain factors. More specifically, the interactions between households and the power grid can be modeled as a non-cooperative stochastic game, where the electricity price is viewed as a stochastic variable. To search for the Nash equilibrium (NE) of the game, we adopt a method based on distributed deep reinforcement learning. Also, the proposed method can preserve the privacy of the households. We then utilize real-world data from Pecan Street Inc., which contains the power consumption profile of more than 1; 000 households, to evaluate the performance of the proposed method. In average, the results reveal that we can achieve around 12% reduction on peak-to-average ratio (PAR) and 11% reduction on load variance. With this approach, the operation cost of the power grid and the electricity cost of the households can be reduced.