 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic coarse co-registration of point clouds from diverse scan geometries: a test of detectors and descriptors
Aug 27, 2023Point clouds are collected nowadays from a plethora of sensors, some having higher accuracies and higher costs, some having lower accuracies but also lower costs. Not only there is a large choice for different sensors, but also these can be transported by different platforms, which can provide different scan geometries. In this work we test the extraction of four different keypoint detectors and three feature descriptors. We benchmark performance in terms of calculation time and we assess their performance in terms of accuracy in their ability in coarse automatic co-registration of two clouds that are collected with different sensors, platforms and scan geometries. One, which we define as having the higher accuracy, and thus will be used as reference, was surveyed via a UAV flight with a Riegl MiniVUX-3, the other on a bicycle with a Livox Horizon over a walking path with un-even ground.The novelty in this work consists in comparing several strategies for fast alignment of point clouds from very different surveying geometries, as the drone has a bird's eye view and the bicycle a ground-based view. An added challenge is related to the lower cost of the bicycle sensor ensemble that, together with the rough terrain, reasonably results in lower accuracy of the survey. The main idea is to use range images to capture a simplified version of the geometry of the surveyed area and then find the best features to match keypoints. Results show that NARF features detected more keypoints and resulted in a faster co-registration procedure in this scenariowhereas the accuracy of the co-registration is similar to all the combinations of keypoint detectors and features.
Hyperspectral and LiDAR data for the prediction via machine learning of tree species, volume and biomass: a possible contribution for updating forest management plans
Sep 30, 2022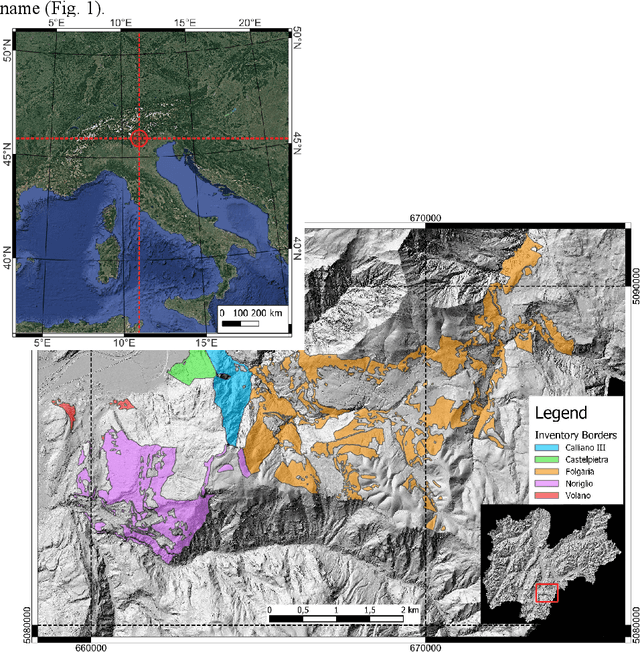
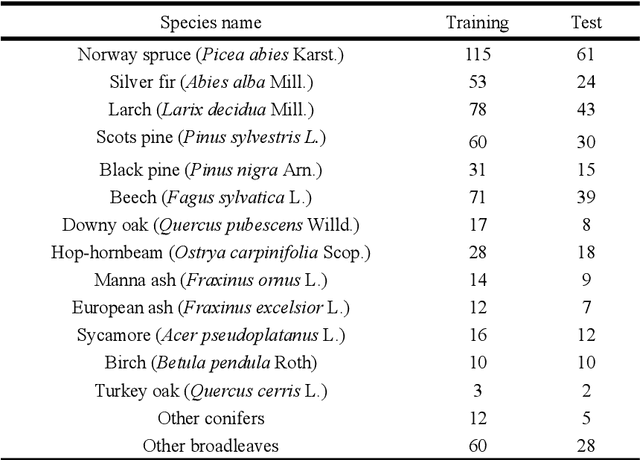
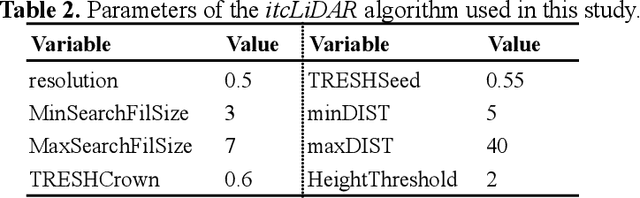

This work intends to lay the foundations for identifying the prevailing forest types and the delineation of forest units within private forest inventories in the Autonomous Province of Trento (PAT), using currently available remote sensing solutions. In particular, data from LiDAR and hyperspectral surveys of 2014 made available by PAT were acquired and processed. Such studies are very important in the context of forest management scenarios. The method includes defining tree species ground-truth by outlining single tree crowns with polygons and labeling them. Successively two supervised machine learning classifiers, K-Nearest Neighborhood and Support Vector Machine (SVM) were used. The results show that, by setting specific hyperparameters, the SVM methodology gave the best results in classification of tree species. Biomass was estimated using canopy parameters and the Jucker equation for the above ground biomass (AGB) and that of Scrinzi for the tariff volume. Predicted values were compared with 11 field plots of fixed radius where volume and biomass were field-estimated in 2017. Results show significant coefficients of correlation: 0.94 for stem volume and 0.90 for total aboveground tree biomass.