 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based optimizer for symmetry finding
May 28, 2026Finding symmetries is crucial for understanding physical models. In this work, we present an optimization framework that searches Pauli symmetries of Hamiltonians, merging the fields of machine learning with automated symmetry finding. Built on a Set-Transformer architecture, our framework uses self-attention to encode the pairwise and higher-order correlations among the Pauli-Strings. The relations are then decoded as a candidate, which is further optimized with a custom commutation-based objective, and mapped to a symmetry of the input Hamiltonian. We apply our method to random Pauli Hamiltonians, periodic one and two dimensional transverse-field Ising model and the Toric code. We show that for physical Hamiltonians (Ising and Toric), our framework succeeds with near-deterministic probability while providing substantial advantage compared to state-of-the-art strategies. For random Pauli Hamiltonians, we estimate the required computational resources, specifically the number of parallel starts and the number of GPUs, to find a symmetry with high success probability under fixed design specifications.
Higher-order topological kernels via quantum computation
Jul 14, 2023


Topological data analysis (TDA) has emerged as a powerful tool for extracting meaningful insights from complex data. TDA enhances the analysis of objects by embedding them into a simplicial complex and extracting useful global properties such as the Betti numbers, i.e. the number of multidimensional holes, which can be used to define kernel methods that are easily integrated with existing machine-learning algorithms. These kernel methods have found broad applications, as they rely on powerful mathematical frameworks which provide theoretical guarantees on their performance. However, the computation of higher-dimensional Betti numbers can be prohibitively expensive on classical hardware, while quantum algorithms can approximate them in polynomial time in the instance size. In this work, we propose a quantum approach to defining topological kernels, which is based on constructing Betti curves, i.e. topological fingerprint of filtrations with increasing order. We exhibit a working prototype of our approach implemented on a noiseless simulator and show its robustness by means of some empirical results suggesting that topological approaches may offer an advantage in quantum machine learning.
Structure Learning of Quantum Embeddings
Sep 22, 2022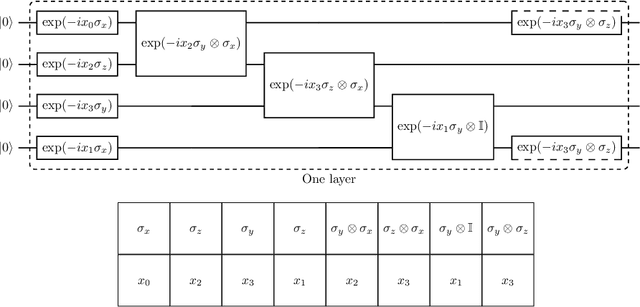
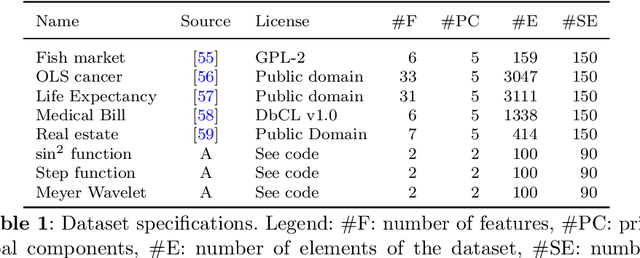
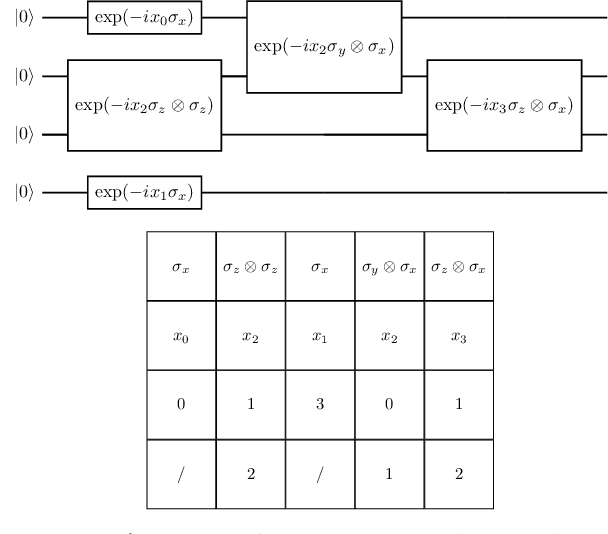
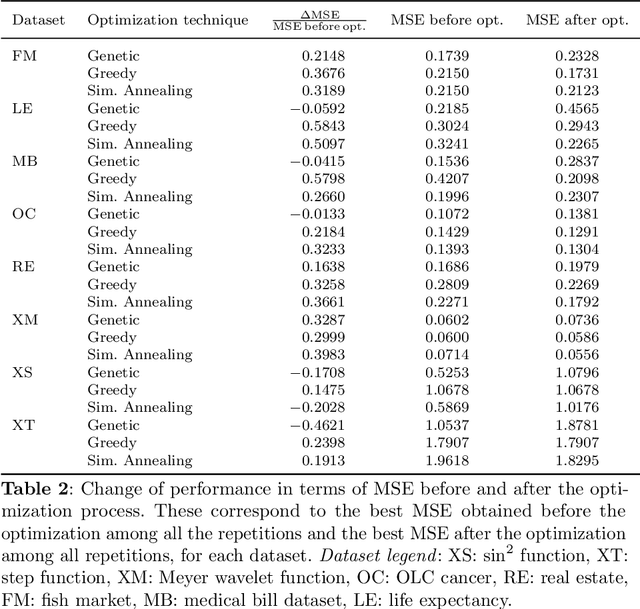
The representation of data is of paramount importance for machine learning methods. Kernel methods are used to enrich the feature representation, allowing better generalization. Quantum kernels implement efficiently complex transformation encoding classical data in the Hilbert space of a quantum system, resulting in even exponential speedup. However, we need prior knowledge of the data to choose an appropriate parametric quantum circuit that can be used as quantum embedding. We propose an algorithm that automatically selects the best quantum embedding through a combinatorial optimization procedure that modifies the structure of the circuit, changing the generators of the gates, their angles (which depend on the data points), and the qubits on which the various gates act. Since combinatorial optimization is computationally expensive, we have introduced a criterion based on the exponential concentration of kernel matrix coefficients around the mean to immediately discard an arbitrarily large portion of solutions that are believed to perform poorly. Contrary to the gradient-based optimization (e.g. trainable quantum kernels), our approach is not affected by the barren plateau by construction. We have used both artificial and real-world datasets to demonstrate the increased performance of our approach with respect to randomly generated PQC. We have also compared the effect of different optimization algorithms, including greedy local search, simulated annealing, and genetic algorithms, showing that the algorithm choice largely affects the result.