 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generic Self-Supervised Framework of Learning Invariant Discriminative Features
Feb 14, 2022

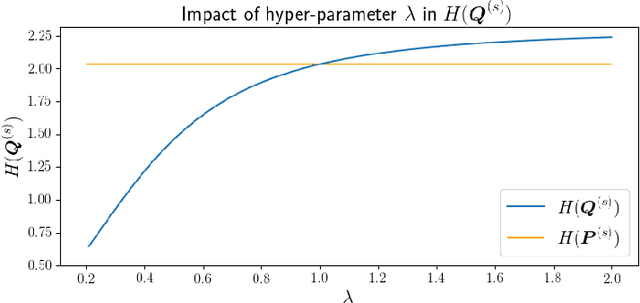
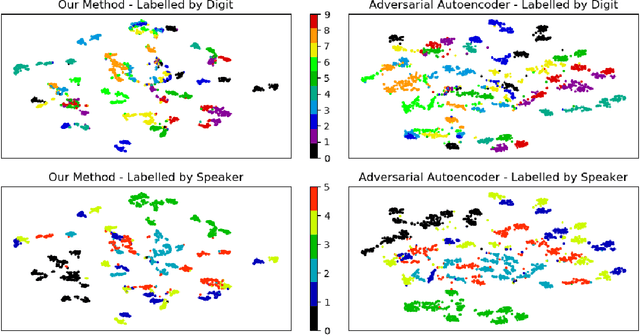
Self-supervised learning (SSL) has become a popular method for generating invariant representations without the need for human annotations. Nonetheless, the desired invariant representation is achieved by utilising prior online transformation functions on the input data. As a result, each SSL framework is customised for a particular data type, e.g., visual data, and further modifications are required if it is used for other dataset types. On the other hand, autoencoder (AE), which is a generic and widely applicable framework, mainly focuses on dimension reduction and is not suited for learning invariant representation. This paper proposes a generic SSL framework based on a constrained self-labelling assignment process that prevents degenerate solutions. Specifically, the prior transformation functions are replaced with a self-transformation mechanism, derived through an unsupervised training process of adversarial training, for imposing invariant representations. Via the self-transformation mechanism, pairs of augmented instances can be generated from the same input data. Finally, a training objective based on contrastive learning is designed by leveraging both the self-labelling assignment and the self-transformation mechanism. Despite the fact that the self-transformation process is very generic, the proposed training strategy outperforms a majority of state-of-the-art representation learning methods based on AE structures. To validate the performance of our method, we conduct experiments on four types of data, namely visual, audio, text, and mass spectrometry data, and compare them in terms of four quantitative metrics. Our comparison results indicate that the proposed method demonstrate robustness and successfully identify patterns within the datasets.
Information Maximization Clustering via Multi-View Self-Labelling
Mar 12, 2021



Image clustering is a particularly challenging computer vision task, which aims to generate annotations without human supervision. Recent advances focus on the use of self-supervised learning strategies in image clustering, by first learning valuable semantics and then clustering the image representations. These multiple-phase algorithms, however, increase the computational time and their final performance is reliant on the first stage. By extending the self-supervised approach, we propose a novel single-phase clustering method that simultaneously learns meaningful representations and assigns the corresponding annotations. This is achieved by integrating a discrete representation into the self-supervised paradigm through a classifier net. Specifically, the proposed clustering objective employs mutual information, and maximizes the dependency between the integrated discrete representation and a discrete probability distribution. The discrete probability distribution is derived though the self-supervised process by comparing the learnt latent representation with a set of trainable prototypes. To enhance the learning performance of the classifier, we jointly apply the mutual information across multi-crop views. Our empirical results show that the proposed framework outperforms state-of-the-art techniques with the average accuracy of 89.1% and 49.0%, respectively, on CIFAR-10 and CIFAR-100/20 datasets. Finally, the proposed method also demonstrates attractive robustness to parameter settings, making it ready to be applicable to other datasets.
Image Clustering using an Augmented Generative Adversarial Network and Information Maximization
Nov 08, 2020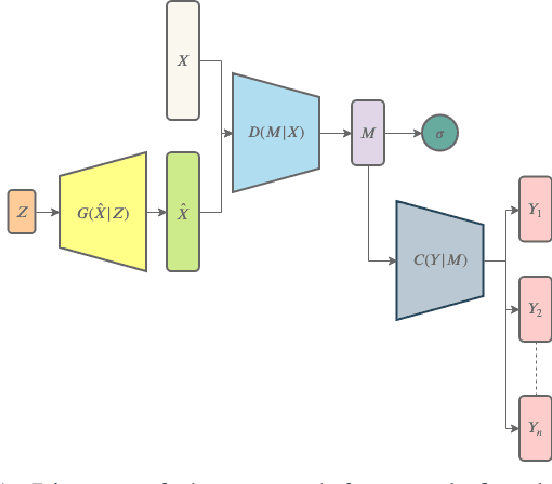



Image clustering has recently attracted significant attention due to the increased availability of unlabelled datasets. The efficiency of traditional clustering algorithms heavily depends on the distance functions used and the dimensionality of the features. Therefore, performance degradation is often observed when tackling either unprocessed images or high-dimensional features extracted from processed images. To deal with these challenges, we propose a deep clustering framework consisting of a modified generative adversarial network (GAN) and an auxiliary classifier. The modification employs Sobel operations prior to the discriminator of the GAN to enhance the separability of the learned features. The discriminator is then leveraged to generate representations as the input to an auxiliary classifier. An adaptive objective function is utilised to train the auxiliary classifier for clustering the representations, aiming to increase the robustness by minimizing the divergence of multiple representations generated by the discriminator. The auxiliary classifier is implemented with a group of multiple cluster-heads, where a tolerance hyper-parameter is used to tackle imbalanced data. Our results indicate that the proposed method significantly outperforms state-of-the-art clustering methods on CIFAR-10 and CIFAR-100, and is competitive on the STL10 and MNIST datasets.