 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgebraic Machine Learning: Learning as computing an algebraic decomposition of a task
Feb 27, 2025Statistics and Optimization are foundational to modern Machine Learning. Here, we propose an alternative foundation based on Abstract Algebra, with mathematics that facilitates the analysis of learning. In this approach, the goal of the task and the data are encoded as axioms of an algebra, and a model is obtained where only these axioms and their logical consequences hold. Although this is not a generalizing model, we show that selecting specific subsets of its breakdown into algebraic atoms obtained via subdirect decomposition gives a model that generalizes. We validate this new learning principle on standard datasets such as MNIST, FashionMNIST, CIFAR-10, and medical images, achieving performance comparable to optimized multilayer perceptrons. Beyond data-driven tasks, the new learning principle extends to formal problems, such as finding Hamiltonian cycles from their specifications and without relying on search. This algebraic foundation offers a fresh perspective on machine intelligence, featuring direct learning from training data without the need for validation dataset, scaling through model additivity, and asymptotic convergence to the underlying rule in the data.
Algebraic Machine Learning
Mar 15, 2018
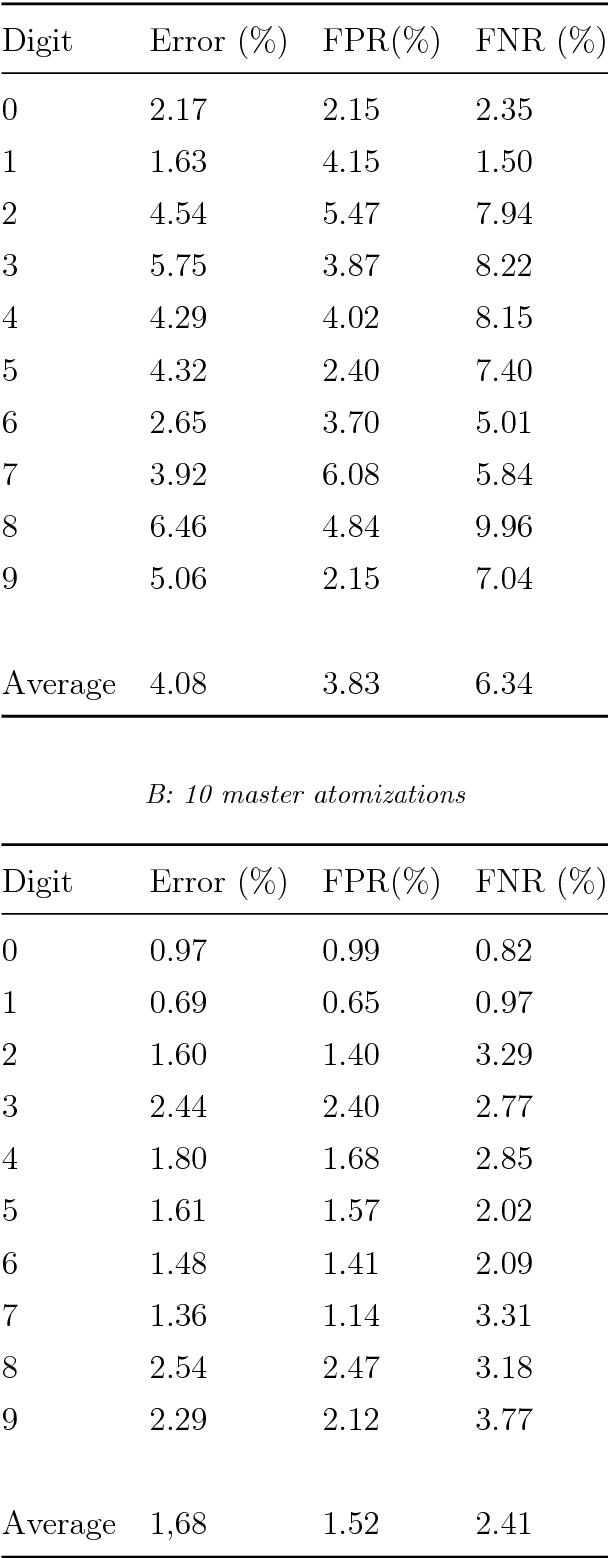

Machine learning algorithms use error function minimization to fit a large set of parameters in a preexisting model. However, error minimization eventually leads to a memorization of the training dataset, losing the ability to generalize to other datasets. To achieve generalization something else is needed, for example a regularization method or stopping the training when error in a validation dataset is minimal. Here we propose a different approach to learning and generalization that is parameter-free, fully discrete and that does not use function minimization. We use the training data to find an algebraic representation with minimal size and maximal freedom, explicitly expressed as a product of irreducible components. This algebraic representation is shown to directly generalize, giving high accuracy in test data, more so the smaller the representation. We prove that the number of generalizing representations can be very large and the algebra only needs to find one. We also derive and test a relationship between compression and error rate. We give results for a simple problem solved step by step, hand-written character recognition, and the Queens Completion problem as an example of unsupervised learning. As an alternative to statistical learning, algebraic learning may offer advantages in combining bottom-up and top-down information, formal concept derivation from data and large-scale parallelization.