 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Evolving Memory Ensembles: Pareto Optimization based on Computational Intelligence for Embedded Memories on a System Level
Sep 20, 2021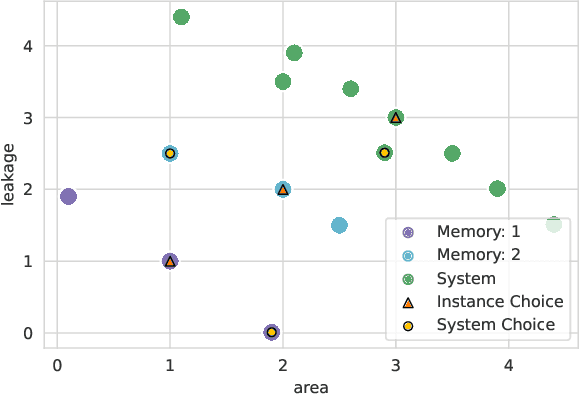

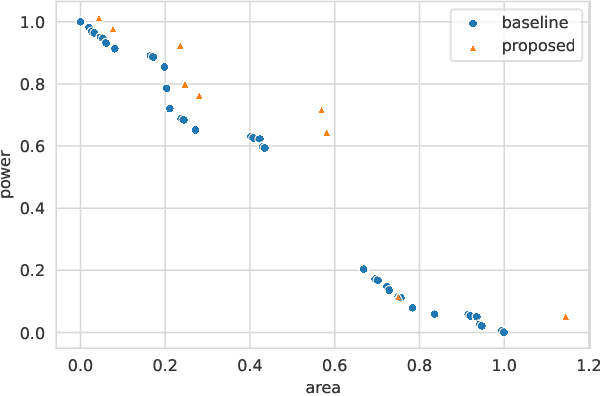
As the relative power, performance, and area (PPA) impact of embedded memories continues to grow, proper parameterization of each of the thousands of memories on a chip is essential. When the parameters of all memories of a product are optimized together as part of a single system, better trade-offs may be achieved than if the same memories were optimized in isolation. However, challenges such as a sparse solution space, conflicting objectives, and computationally expensive PPA estimation impede the application of common optimization heuristics. We show how the memory system optimization problem can be solved through computational intelligence. We apply a Pareto-based Differential Evolution to ensure unbiased optimization of multiple PPA objectives. To ensure efficient exploration of a sparse solution space, we repair individuals to yield feasible parameterizations. PPA is estimated efficiently in large batches by pre-trained regression neural networks. Our framework enables the system optimization of thousands of memories while keeping a small resource footprint. Evaluating our method on a tractable system, we find that our method finds diverse solutions which exhibit less than 0.5% distance from known global optima.
Predicting Memory Compiler Performance Outputs using Feed-Forward Neural Networks
Mar 05, 2020



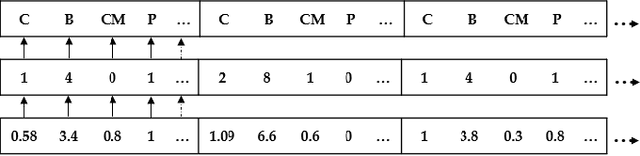
Typical semiconductor chips include thousands of mostly small memories. As memories contribute an estimated 25% to 40% to the overall power, performance, and area (PPA) of a chip, memories must be designed carefully to meet the system's requirements. Memory arrays are highly uniform and can be described by approximately 10 parameters depending mostly on the complexity of the periphery. Thus, to improve PPA utilization, memories are typically generated by memory compilers. A key task in the design flow of a chip is to find optimal memory compiler parametrizations which on the one hand fulfill system requirements while on the other hand optimize PPA. Although most compiler vendors also provide optimizers for this task, these are often slow or inaccurate. To enable efficient optimization in spite of long compiler run times, we propose training fully connected feed-forward neural networks to predict PPA outputs given a memory compiler parametrization. Using an exhaustive search-based optimizer framework which obtains neural network predictions, PPA-optimal parametrizations are found within seconds after chip designers have specified their requirements. Average model prediction errors of less than 3%, a decision reliability of over 99% and productive usage of the optimizer for successful, large volume chip design projects illustrate the effectiveness of the approach.
Oversampling for Imbalanced Learning Based on K-Means and SMOTE
Dec 12, 2017

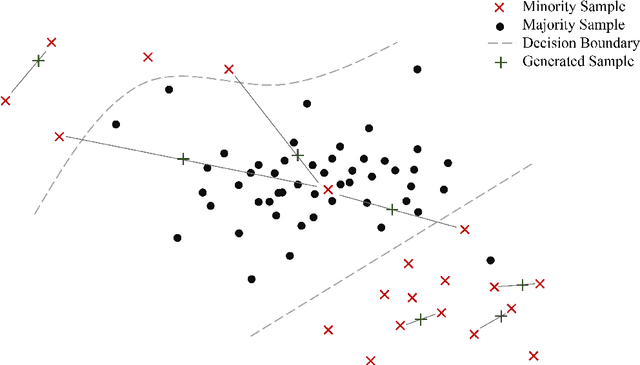
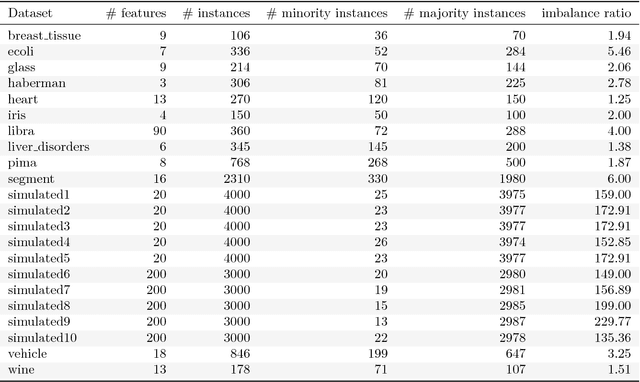
Learning from class-imbalanced data continues to be a common and challenging problem in supervised learning as standard classification algorithms are designed to handle balanced class distributions. While different strategies exist to tackle this problem, methods which generate artificial data to achieve a balanced class distribution are more versatile than modifications to the classification algorithm. Such techniques, called oversamplers, modify the training data, allowing any classifier to be used with class-imbalanced datasets. Many algorithms have been proposed for this task, but most are complex and tend to generate unnecessary noise. This work presents a simple and effective oversampling method based on k-means clustering and SMOTE oversampling, which avoids the generation of noise and effectively overcomes imbalances between and within classes. Empirical results of extensive experiments with 71 datasets show that training data oversampled with the proposed method improves classification results. Moreover, k-means SMOTE consistently outperforms other popular oversampling methods. An implementation is made available in the python programming language.