 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbolic Knowledge Extraction and Injection with Sub-symbolic Predictors: A Systematic Literature Review
Jan 23, 2025In this paper we focus on the opacity issue of sub-symbolic machine learning predictors by promoting two complementary activities, namely, symbolic knowledge extraction (SKE) and injection (SKI) from and into sub-symbolic predictors. We consider as symbolic any language being intelligible and interpretable for both humans and computers. Accordingly, we propose general meta-models for both SKE and SKI, along with two taxonomies for the classification of SKE and SKI methods. By adopting an explainable artificial intelligence (XAI) perspective, we highlight how such methods can be exploited to mitigate the aforementioned opacity issue. Our taxonomies are attained by surveying and classifying existing methods from the literature, following a systematic approach, and by generalising the results of previous surveys targeting specific sub-topics of either SKE or SKI alone. More precisely, we analyse 132 methods for SKE and 117 methods for SKI, and we categorise them according to their purpose, operation, expected input/output data and predictor types. For each method, we also indicate the presence/lack of runnable software implementations. Our work may be of interest for data scientists aiming at selecting the most adequate SKE/SKI method for their needs, and also work as suggestions for researchers interested in filling the gaps of the current state of the art, as well as for developers willing to implement SKE/SKI-based technologies.
Evaluating Machine Learning Models against Clinical Protocols for Enhanced Interpretability and Continuity of Care
Nov 05, 2024



In clinical practice, decision-making relies heavily on established protocols, often formalised as rules. Concurrently, Machine Learning (ML) models, trained on clinical data, aspire to integrate into medical decision-making processes. However, despite the growing number of ML applications, their adoption into clinical practice remains limited. Two critical concerns arise, relevant to the notions of consistency and continuity of care: (a) accuracy - the ML model, albeit more accurate, might introduce errors that would not have occurred by applying the protocol; (b) interpretability - ML models operating as black boxes might make predictions based on relationships that contradict established clinical knowledge. In this context, the literature suggests using ML models integrating domain knowledge for improved accuracy and interpretability. However, there is a lack of appropriate metrics for comparing ML models with clinical rules in addressing these challenges. Accordingly, in this article, we first propose metrics to assess the accuracy of ML models with respect to the established protocol. Secondly, we propose an approach to measure the distance of explanations provided by two rule sets, with the goal of comparing the explanation similarity between clinical rule-based systems and rules extracted from ML models. The approach is validated on the Pima Indians Diabetes dataset by training two neural networks - one exclusively on data, and the other integrating a clinical protocol. Our findings demonstrate that the integrated ML model achieves comparable performance to that of a fully data-driven model while exhibiting superior accuracy relative to the clinical protocol, ensuring enhanced continuity of care. Furthermore, we show that our integrated model provides explanations for predictions that align more closely with the clinical protocol compared to the data-driven model.
Solar Wind Speed Estimate with Machine Learning Ensemble Models for LISA
Feb 13, 2023



In this work we study the potentialities of machine learning models in reconstructing the solar wind speed observations gathered in the first Lagrangian point by the ACE satellite in 2016--2017 using as input data galactic cosmic-ray flux variations measured with particle detectors hosted onboard the LISA Pathfinder mission also orbiting around L1 during the same years. We show that ensemble models composed of heterogeneous weak regressors are able to outperform weak regressors in terms of predictive accuracy. Machine learning and other powerful predictive algorithms open a window on the possibility of substituting dedicated instrumentation with software models acting as surrogates for diagnostics of space missions such as LISA and space weather science.
Evaluation Metrics for Symbolic Knowledge Extracted from Machine Learning Black Boxes: A Discussion Paper
Nov 01, 2022As opaque decision systems are being increasingly adopted in almost any application field, issues about their lack of transparency and human readability are a concrete concern for end-users. Amongst existing proposals to associate human-interpretable knowledge with accurate predictions provided by opaque models, there are rule extraction techniques, capable of extracting symbolic knowledge out of an opaque model. However, how to assess the level of readability of the extracted knowledge quantitatively is still an open issue. Finding such a metric would be the key, for instance, to enable automatic comparison between a set of different knowledge representations, paving the way for the development of parameter autotuning algorithms for knowledge extractors. In this paper we discuss the need for such a metric as well as the criticalities of readability assessment and evaluation, taking into account the most common knowledge representations while highlighting the most puzzling issues.
Clustering-Based Approaches for Symbolic Knowledge Extraction
Nov 01, 2022

Opaque models belonging to the machine learning world are ever more exploited in the most different application areas. These models, acting as black boxes (BB) from the human perspective, cannot be entirely trusted if the application is critical unless there exists a method to extract symbolic and human-readable knowledge out of them. In this paper we analyse a recurrent design adopted by symbolic knowledge extractors for BB regressors - that is, the creation of rules associated with hypercubic input space regions. We argue that this kind of partitioning may lead to suboptimal solutions when the data set at hand is high-dimensional or does not satisfy symmetric constraints. We then propose a (deep) clustering-based approach to be performed before symbolic knowledge extraction to achieve better performance with data sets of any kind.
Symbolic Knowledge Extraction from Opaque Predictors Applied to Cosmic-Ray Data Gathered with LISA Pathfinder
Sep 10, 2022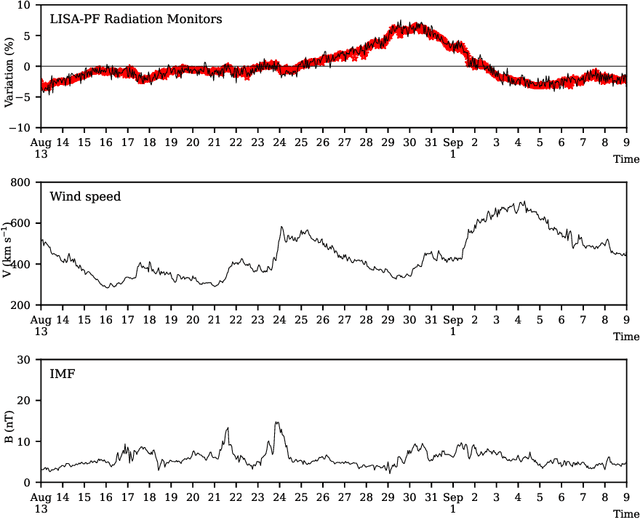
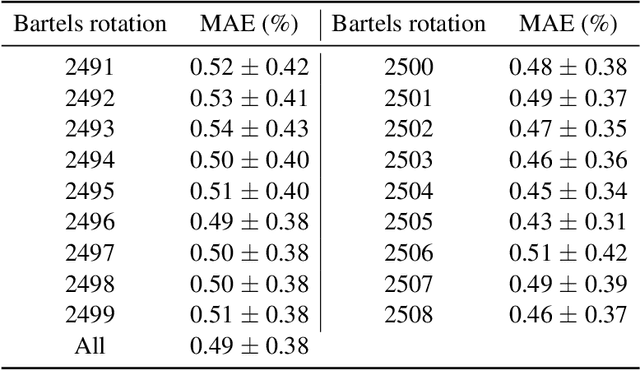
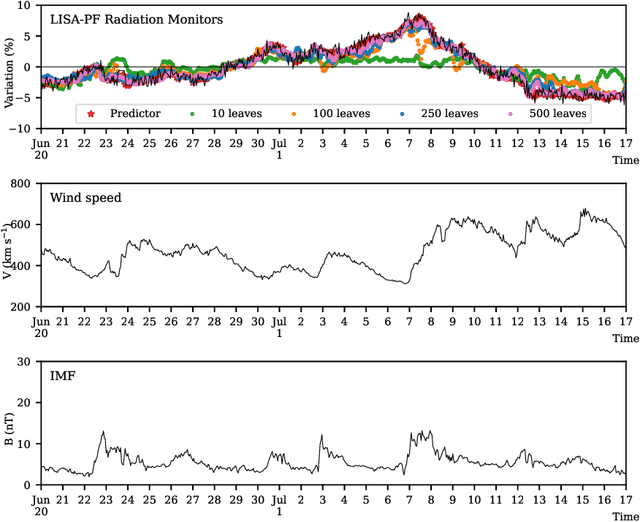
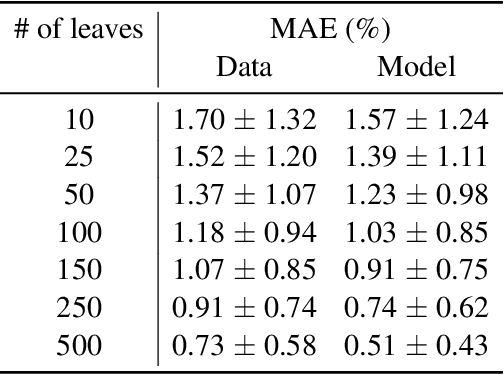
Machine learning models are nowadays ubiquitous in space missions, performing a wide variety of tasks ranging from the prediction of multivariate time series through the detection of specific patterns in the input data. Adopted models are usually deep neural networks or other complex machine learning algorithms providing predictions that are opaque, i.e., human users are not allowed to understand the rationale behind the provided predictions. Several techniques exist in the literature to combine the impressive predictive performance of opaque machine learning models with human-intelligible prediction explanations, as for instance the application of symbolic knowledge extraction procedures. In this paper are reported the results of different knowledge extractors applied to an ensemble predictor capable of reproducing cosmic-ray data gathered on board the LISA Pathfinder space mission. A discussion about the readability/fidelity trade-off of the extracted knowledge is also presented.