 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Machine Learning into Belief-Desire-Intention Agents: Current Advances and Open Challenges
Oct 23, 2025
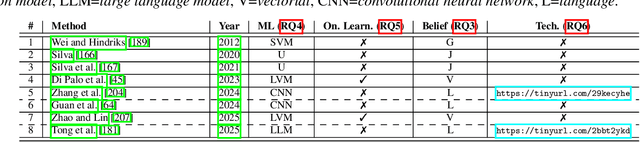
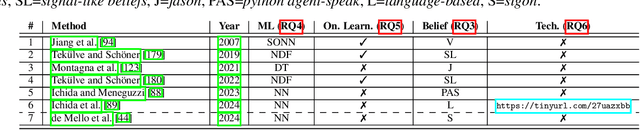

Thanks to the remarkable human-like capabilities of machine learning (ML) models in perceptual and cognitive tasks, frameworks integrating ML within rational agent architectures are gaining traction. Yet, the landscape remains fragmented and incoherent, often focusing on embedding ML into generic agent containers while overlooking the expressive power of rational architectures--such as Belief-Desire-Intention (BDI) agents. This paper presents a fine-grained systematisation of existing approaches, using the BDI paradigm as a reference. Our analysis illustrates the fast-evolving literature on rational agents enhanced by ML, and identifies key research opportunities and open challenges for designing effective rational ML agents.
Symbolic Knowledge Extraction and Injection with Sub-symbolic Predictors: A Systematic Literature Review
Jan 23, 2025In this paper we focus on the opacity issue of sub-symbolic machine learning predictors by promoting two complementary activities, namely, symbolic knowledge extraction (SKE) and injection (SKI) from and into sub-symbolic predictors. We consider as symbolic any language being intelligible and interpretable for both humans and computers. Accordingly, we propose general meta-models for both SKE and SKI, along with two taxonomies for the classification of SKE and SKI methods. By adopting an explainable artificial intelligence (XAI) perspective, we highlight how such methods can be exploited to mitigate the aforementioned opacity issue. Our taxonomies are attained by surveying and classifying existing methods from the literature, following a systematic approach, and by generalising the results of previous surveys targeting specific sub-topics of either SKE or SKI alone. More precisely, we analyse 132 methods for SKE and 117 methods for SKI, and we categorise them according to their purpose, operation, expected input/output data and predictor types. For each method, we also indicate the presence/lack of runnable software implementations. Our work may be of interest for data scientists aiming at selecting the most adequate SKE/SKI method for their needs, and also work as suggestions for researchers interested in filling the gaps of the current state of the art, as well as for developers willing to implement SKE/SKI-based technologies.
Large language models as oracles for instantiating ontologies with domain-specific knowledge
Apr 05, 2024Background. Endowing intelligent systems with semantic data commonly requires designing and instantiating ontologies with domain-specific knowledge. Especially in the early phases, those activities are typically performed manually by human experts possibly leveraging on their own experience. The resulting process is therefore time-consuming, error-prone, and often biased by the personal background of the ontology designer. Objective. To mitigate that issue, we propose a novel domain-independent approach to automatically instantiate ontologies with domain-specific knowledge, by leveraging on large language models (LLMs) as oracles. Method. Starting from (i) an initial schema composed by inter-related classes andproperties and (ii) a set of query templates, our method queries the LLM multi- ple times, and generates instances for both classes and properties from its replies. Thus, the ontology is automatically filled with domain-specific knowledge, compliant to the initial schema. As a result, the ontology is quickly and automatically enriched with manifold instances, which experts may consider to keep, adjust, discard, or complement according to their own needs and expertise. Contribution. We formalise our method in general way and instantiate it over various LLMs, as well as on a concrete case study. We report experiments rooted in the nutritional domain where an ontology of food meals and their ingredients is semi-automatically instantiated from scratch, starting from a categorisation of meals and their relationships. There, we analyse the quality of the generated ontologies and compare ontologies attained by exploiting different LLMs. Finally, we provide a SWOT analysis of the proposed method.