 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sound of Silence: Efficiency of First Digit Features in Synthetic Audio Detection
Oct 06, 2022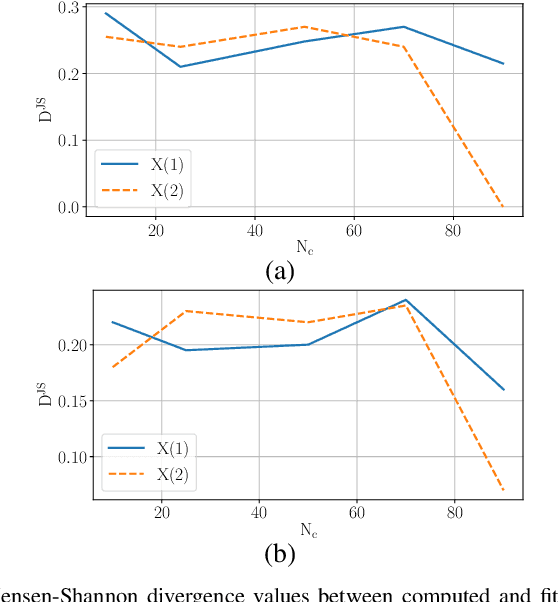
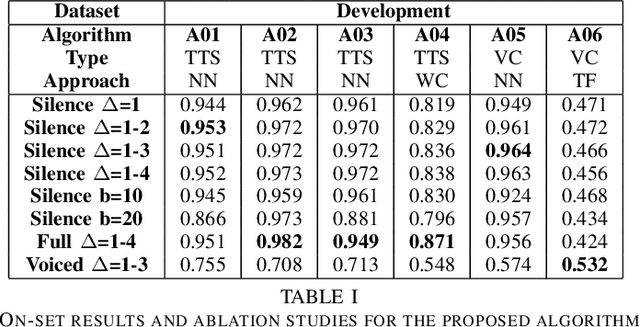
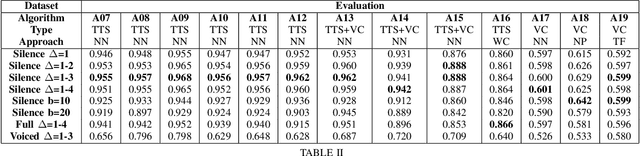
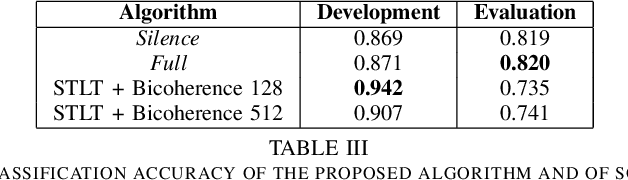
The recent integration of generative neural strategies and audio processing techniques have fostered the widespread of synthetic speech synthesis or transformation algorithms. This capability proves to be harmful in many legal and informative processes (news, biometric authentication, audio evidence in courts, etc.). Thus, the development of efficient detection algorithms is both crucial and challenging due to the heterogeneity of forgery techniques. This work investigates the discriminative role of silenced parts in synthetic speech detection and shows how first digit statistics extracted from MFCC coefficients can efficiently enable a robust detection. The proposed procedure is computationally-lightweight and effective on many different algorithms since it does not rely on large neural detection architecture and obtains an accuracy above 90\% in most of the classes of the ASVSpoof dataset.