 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Tracking Translation: A Comprehensive Analysis of Visual SLAM in Human-Centered XR and IoT Ecosystems
Nov 11, 2024



Advancements in tracking algorithms have empowered nascent applications across various domains, from steering autonomous vehicles to guiding robots to enhancing augmented reality experiences for users. However, these algorithms are application-specific and do not work across applications with different types of motion; even a tracking algorithm designed for a given application does not work in scenarios deviating from highly standard conditions. For example, a tracking algorithm designed for robot navigation inside a building will not work for tracking the same robot in an outdoor environment. To demonstrate this problem, we evaluate the performance of the state-of-the-art tracking methods across various applications and scenarios. To inform our analysis, we first categorize algorithmic, environmental, and locomotion-related challenges faced by tracking algorithms. We quantitatively evaluate the performance using multiple tracking algorithms and representative datasets for a wide range of Internet of Things (IoT) and Extended Reality (XR) applications, including autonomous vehicles, drones, and humans. Our analysis shows that no tracking algorithm works across different applications and scenarios within applications. Ultimately, using the insights generated from our analysis, we discuss multiple approaches to improving the tracking performance using input data characterization, leveraging intermediate information, and output evaluation.
A Neurosymbolic Approach to Adaptive Feature Extraction in SLAM
Jul 09, 2024Autonomous robots, autonomous vehicles, and humans wearing mixed-reality headsets require accurate and reliable tracking services for safety-critical applications in dynamically changing real-world environments. However, the existing tracking approaches, such as Simultaneous Localization and Mapping (SLAM), do not adapt well to environmental changes and boundary conditions despite extensive manual tuning. On the other hand, while deep learning-based approaches can better adapt to environmental changes, they typically demand substantial data for training and often lack flexibility in adapting to new domains. To solve this problem, we propose leveraging the neurosymbolic program synthesis approach to construct adaptable SLAM pipelines that integrate the domain knowledge from traditional SLAM approaches while leveraging data to learn complex relationships. While the approach can synthesize end-to-end SLAM pipelines, we focus on synthesizing the feature extraction module. We first devise a domain-specific language (DSL) that can encapsulate domain knowledge on the important attributes for feature extraction and the real-world performance of various feature extractors. Our neurosymbolic architecture then undertakes adaptive feature extraction, optimizing parameters via learning while employing symbolic reasoning to select the most suitable feature extractor. Our evaluations demonstrate that our approach, neurosymbolic Feature EXtraction (nFEX), yields higher-quality features. It also reduces the pose error observed for the state-of-the-art baseline feature extractors ORB and SIFT by up to 90% and up to 66%, respectively, thereby enhancing the system's efficiency and adaptability to novel environments.
Mitigating Group Bias in Federated Learning for Heterogeneous Devices
Sep 13, 2023Federated Learning is emerging as a privacy-preserving model training approach in distributed edge applications. As such, most edge deployments are heterogeneous in nature i.e., their sensing capabilities and environments vary across deployments. This edge heterogeneity violates the independence and identical distribution (IID) property of local data across clients and produces biased global models i.e. models that contribute to unfair decision-making and discrimination against a particular community or a group. Existing bias mitigation techniques only focus on bias generated from label heterogeneity in non-IID data without accounting for domain variations due to feature heterogeneity and do not address global group-fairness property. Our work proposes a group-fair FL framework that minimizes group-bias while preserving privacy and without resource utilization overhead. Our main idea is to leverage average conditional probabilities to compute a cross-domain group \textit{importance weights} derived from heterogeneous training data to optimize the performance of the worst-performing group using a modified multiplicative weights update method. Additionally, we propose regularization techniques to minimize the difference between the worst and best-performing groups while making sure through our thresholding mechanism to strike a balance between bias reduction and group performance degradation. Our evaluation of human emotion recognition and image classification benchmarks assesses the fair decision-making of our framework in real-world heterogeneous settings.
Realizing Uncertainty-Aware Timing Stack in Embedded Operating System
Feb 03, 2018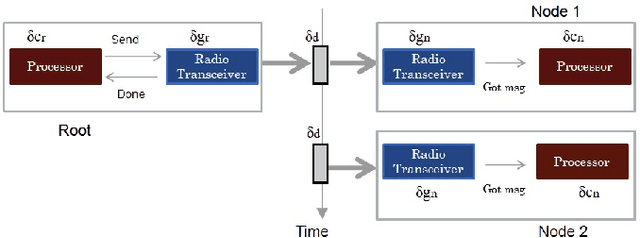

Time awareness is critical to a broad range of emerging applications -- in Cyber-Physical Systems and Internet of Things -- running on commodity platforms and operating systems. Traditionally, time is synchronized across devices through a best-effort background service whose performance is neither observable nor controllable, thus consuming system resources independently of application needs while not allowing the applications and OS services to adapt to changes in uncertainty in system time. We advocate for rethinking how time is managed in a system stack. In this paper, we propose a new clock model that characterizes various sources of timing uncertainties in true time. We then present a Kalman filter based time synchronization protocol that adapts to the uncertainties exposed by the clock model. Our realization of a uncertainty-aware clock model and synchronization protocol is based on a standard embedded Linux platform.