 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Black Box Testing of Sentiment Analysis Classification Networks
Jul 30, 2024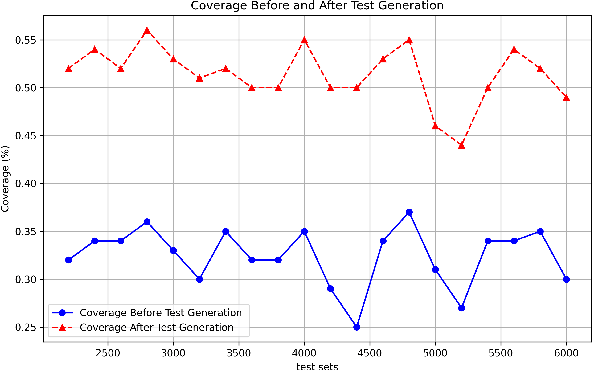
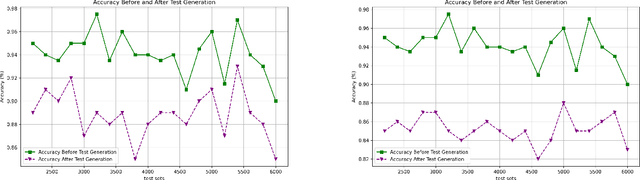
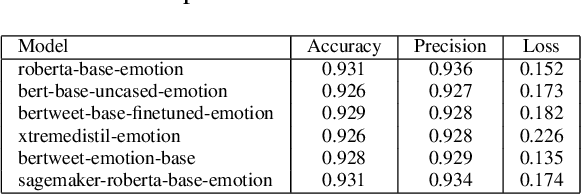
Transformer-based neural networks have demonstrated remarkable performance in natural language processing tasks such as sentiment analysis. Nevertheless, the issue of ensuring the dependability of these complicated architectures through comprehensive testing is still open. This paper presents a collection of coverage criteria specifically designed to assess test suites created for transformer-based sentiment analysis networks. Our approach utilizes input space partitioning, a black-box method, by considering emotionally relevant linguistic features such as verbs, adjectives, adverbs, and nouns. In order to effectively produce test cases that encompass a wide range of emotional elements, we utilize the k-projection coverage metric. This metric minimizes the complexity of the problem by examining subsets of k features at the same time, hence reducing dimensionality. Large language models are employed to generate sentences that display specific combinations of emotional features. The findings from experiments obtained from a sentiment analysis dataset illustrate that our criteria and generated tests have led to an average increase of 16\% in test coverage. In addition, there is a corresponding average decrease of 6.5\% in model accuracy, showing the ability to identify vulnerabilities. Our work provides a foundation for improving the dependability of transformer-based sentiment analysis systems through comprehensive test evaluation.
DeepCover: Advancing RNN Test Coverage and Online Error Prediction using State Machine Extraction
Feb 10, 2024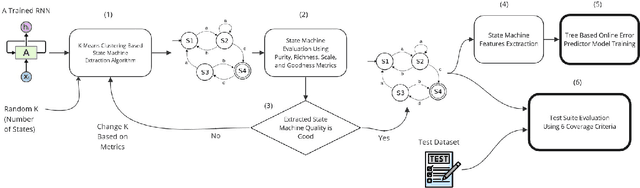

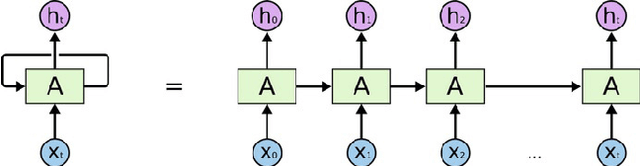
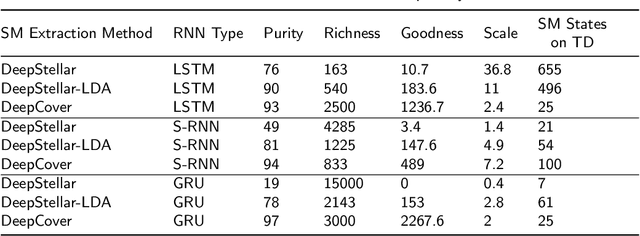
Recurrent neural networks (RNNs) have emerged as powerful tools for processing sequential data in various fields, including natural language processing and speech recognition. However, the lack of explainability in RNN models has limited their interpretability, posing challenges in understanding their internal workings. To address this issue, this paper proposes a methodology for extracting a state machine (SM) from an RNN-based model to provide insights into its internal function. The proposed SM extraction algorithm was assessed using four newly proposed metrics: Purity, Richness, Goodness, and Scale. The proposed methodology along with its assessment metrics contribute to increasing explainability in RNN models by providing a clear representation of their internal decision making process through the extracted SM. In addition to improving the explainability of RNNs, the extracted SM can be used to advance testing and and monitoring of the primary RNN-based model. To enhance RNN testing, we introduce six model coverage criteria based on the extracted SM, serving as metrics for evaluating the effectiveness of test suites designed to analyze the primary model. We also propose a tree-based model to predict the error probability of the primary model for each input based on the extracted SM. We evaluated our proposed online error prediction approach using the MNIST dataset and Mini Speech Commands dataset, achieving an area under the curve (AUC) exceeding 80\% for the receiver operating characteristic (ROC) chart.
A Passive Online Technique for Learning Hybrid Automata from Input/Output Traces
Jan 18, 2021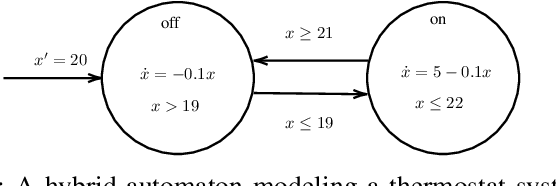
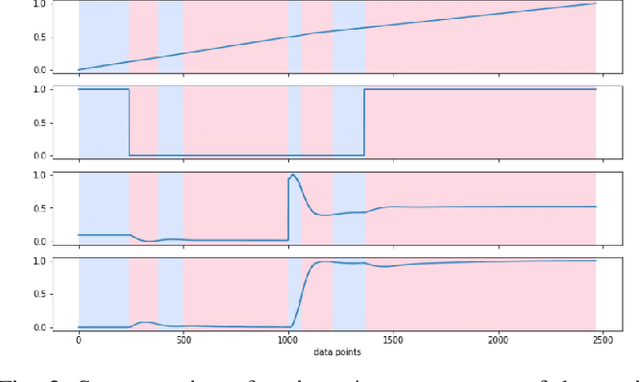
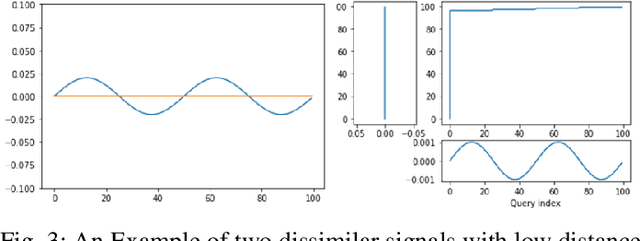
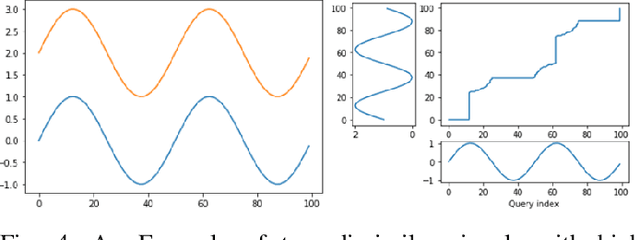
Specification synthesis is the process of deriving a model from the input-output traces of a system. It is used extensively in test design, reverse engineering, and system identification. One type of the resulting artifact of this process for cyber-physical systems is hybrid automata. They are intuitive, precise, tool independent, and at a high level of abstraction, and can model systems with both discrete and continuous variables. In this paper, we propose a new technique for synthesizing hybrid automaton from the input-output traces of a non-linear cyber-physical system. Similarity detection in non-linear behaviors is the main challenge for extracting such models. We address this problem by utilizing the Dynamic Time Warping technique. Our approach is passive, meaning that it does not need interaction with the system during automata synthesis from the logged traces; and online, which means that each input/output trace is used only once in the procedure. In other words, each new trace can be used to improve the already synthesized automaton. We evaluated our algorithm in two industrial and simulated case studies. The accuracy of the derived automata show promising results.
Self-Competitive Neural Networks
Aug 22, 2020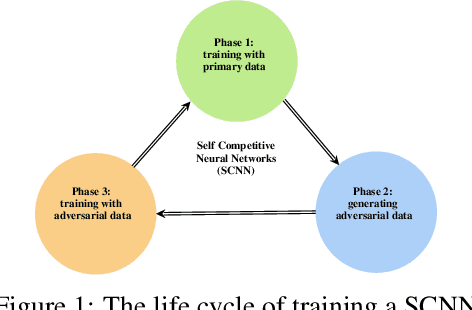

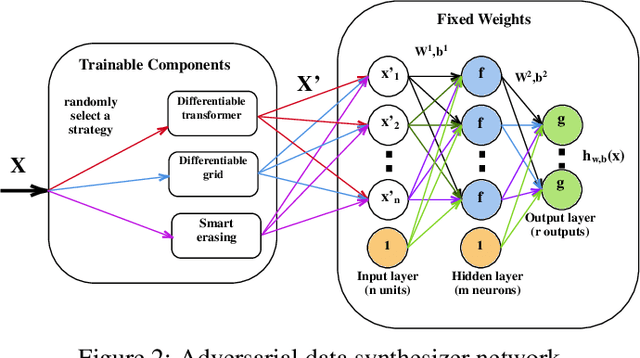

Deep Neural Networks (DNNs) have improved the accuracy of classification problems in lots of applications. One of the challenges in training a DNN is its need to be fed by an enriched dataset to increase its accuracy and avoid it suffering from overfitting. One way to improve the generalization of DNNs is to augment the training data with new synthesized adversarial samples. Recently, researchers have worked extensively to propose methods for data augmentation. In this paper, we generate adversarial samples to refine the Domains of Attraction (DoAs) of each class. In this approach, at each stage, we use the model learned by the primary and generated adversarial data (up to that stage) to manipulate the primary data in a way that look complicated to the DNN. The DNN is then retrained using the augmented data and then it again generates adversarial data that are hard to predict for itself. As the DNN tries to improve its accuracy by competing with itself (generating hard samples and then learning them), the technique is called Self-Competitive Neural Network (SCNN). To generate such samples, we pose the problem as an optimization task, where the network weights are fixed and use a gradient descent based method to synthesize adversarial samples that are on the boundary of their true labels and the nearest wrong labels. Our experimental results show that data augmentation using SCNNs can significantly increase the accuracy of the original network. As an example, we can mention improving the accuracy of a CNN trained with 1000 limited training data of MNIST dataset from 94.26% to 98.25%.