 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerPaDa: A Persian Paraphrase Dataset based on Implicit Crowdsourcing Data Collection
Jan 17, 2022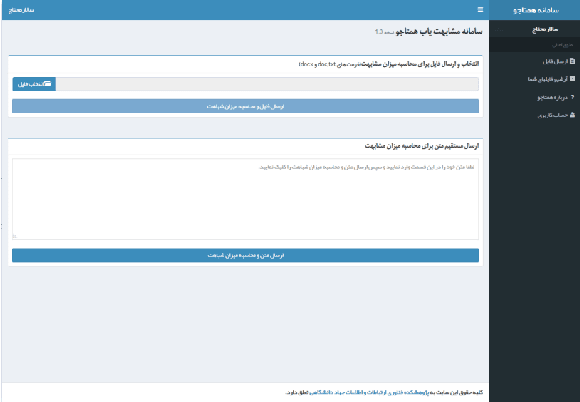
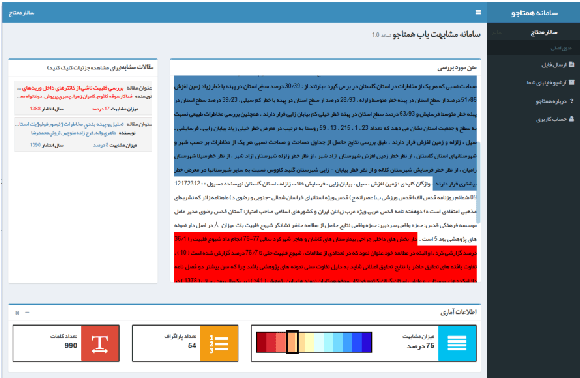
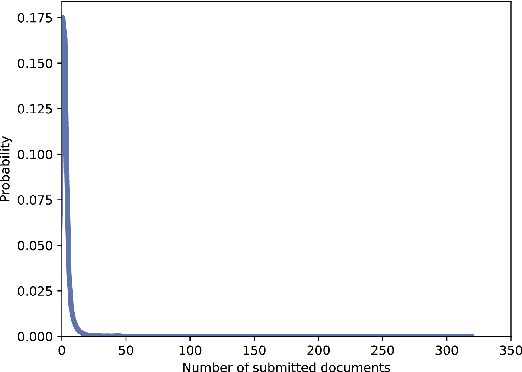
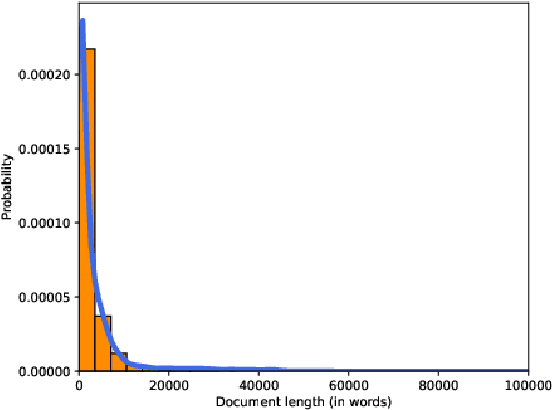
In this paper we introduce PerPaDa, a Persian paraphrase dataset that is collected from users' input in a plagiarism detection system. As an implicit crowdsourcing experience, we have gathered a large collection of original and paraphrased sentences from Hamtajoo; a Persian plagiarism detection system, in which users try to conceal cases of text re-use in their documents by paraphrasing and re-submitting manuscripts for analysis. The compiled dataset contains 2446 instances of paraphrasing. In order to improve the overall quality of the collected data, some heuristics have been used to exclude sentences that don't meet the proposed criteria. The introduced corpus is much larger than the available datasets for the task of paraphrase identification in Persian. Moreover, there is less bias in the data compared to the similar datasets, since the users did not try some fixed predefined rules in order to generate similar texts to their original inputs.