 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgesubMFL: Compatiple subModel Generation for Federated Learning in Device Heterogenous Environment
May 30, 2024Federated Learning (FL) is commonly used in systems with distributed and heterogeneous devices with access to varying amounts of data and diverse computing and storage capacities. FL training process enables such devices to update the weights of a shared model locally using their local data and then a trusted central server combines all of those models to generate a global model. In this way, a global model is generated while the data remains local to devices to preserve privacy. However, training large models such as Deep Neural Networks (DNNs) on resource-constrained devices can take a prohibitively long time and consume a large amount of energy. In the current process, the low-capacity devices are excluded from the training process, although they might have access to unseen data. To overcome this challenge, we propose a model compression approach that enables heterogeneous devices with varying computing capacities to participate in the FL process. In our approach, the server shares a dense model with all devices to train it: Afterwards, the trained model is gradually compressed to obtain submodels with varying levels of sparsity to be used as suitable initial global models for resource-constrained devices that were not capable of train the first dense model. This results in an increased participation rate of resource-constrained devices while the transferred weights from the previous round of training are preserved. Our validation experiments show that despite reaching about 50 per cent global sparsity, generated submodels maintain their accuracy while can be shared to increase participation by around 50 per cent.
Ontology-Enhanced Decision-Making for Autonomous Agents in Dynamic and Partially Observable Environments
May 27, 2024



Agents, whether software or hardware, perceive their environment through sensors and act using actuators, often operating in dynamic, partially observable settings. They face challenges like incomplete and noisy data, unforeseen situations, and the need to adapt goals in real-time. Traditional reasoning and ML methods, including Reinforcement Learning (RL), help but are limited by data needs, predefined goals, and extensive exploration periods. Ontologies offer a solution by integrating diverse information sources, enhancing decision-making in complex environments. This thesis introduces an ontology-enhanced decision-making model (OntoDeM) for autonomous agents. OntoDeM enriches agents' domain knowledge, allowing them to interpret unforeseen events, generate or adapt goals, and make better decisions. Key contributions include: 1. An ontology-based method to improve agents' real-time observations using prior knowledge. 2. The OntoDeM model for handling dynamic, unforeseen situations by evolving or generating new goals. 3. Implementation and evaluation in four real-world applications, demonstrating its effectiveness. Compared to traditional and advanced learning algorithms, OntoDeM shows superior performance in improving agents' observations and decision-making in dynamic, partially observable environments.
Multi-Value Alignment in Normative Multi-Agent System: Evolutionary Optimisation Approach
May 12, 2023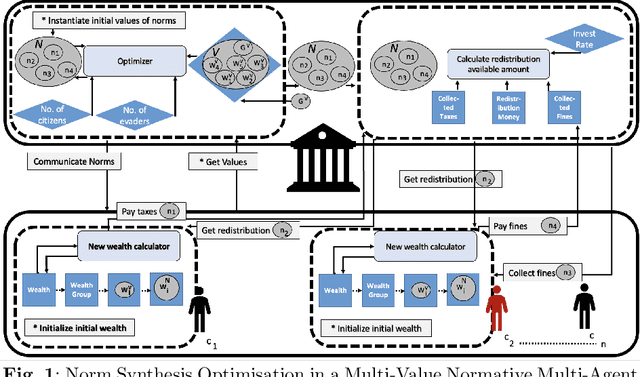
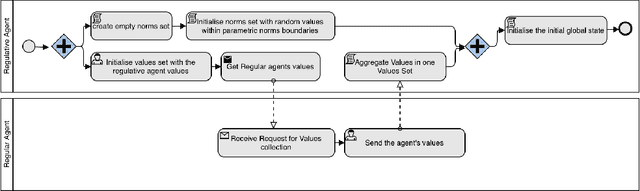
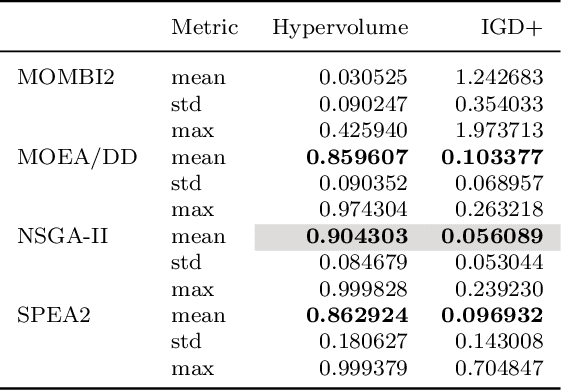
Value-alignment in normative multi-agent systems is used to promote a certain value and to ensure the consistent behavior of agents in autonomous intelligent systems with human values. However, the current literature is limited to incorporation of effective norms for single value alignment with no consideration of agents' heterogeneity and the requirement of simultaneous promotion and alignment of multiple values. This research proposes a multi-value promotion model that uses multi-objective evolutionary algorithms to produce the optimum parametric set of norms that is aligned with multiple simultaneous values of heterogeneous agents and the system. To understand various aspects of this complex problem, several evolutionary algorithms were used to find a set of optimised norm parameters considering two toy tax scenarios with two and five values are considered. The results are analysed from different perspectives to show the impact of a selected evolutionary algorithm on the solution, and the importance of understanding the relation between values when prioritising them.