 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond algorithm hyperparameters: on preprocessing hyperparameters and associated pitfalls in machine learning applications
Dec 04, 2024

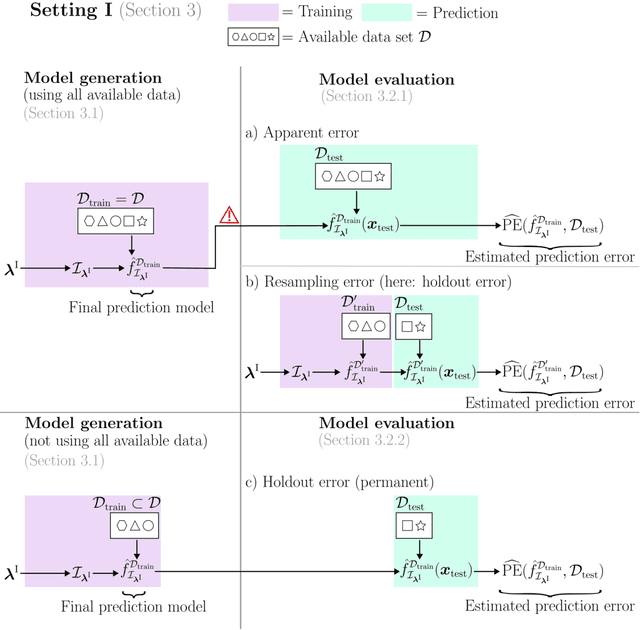
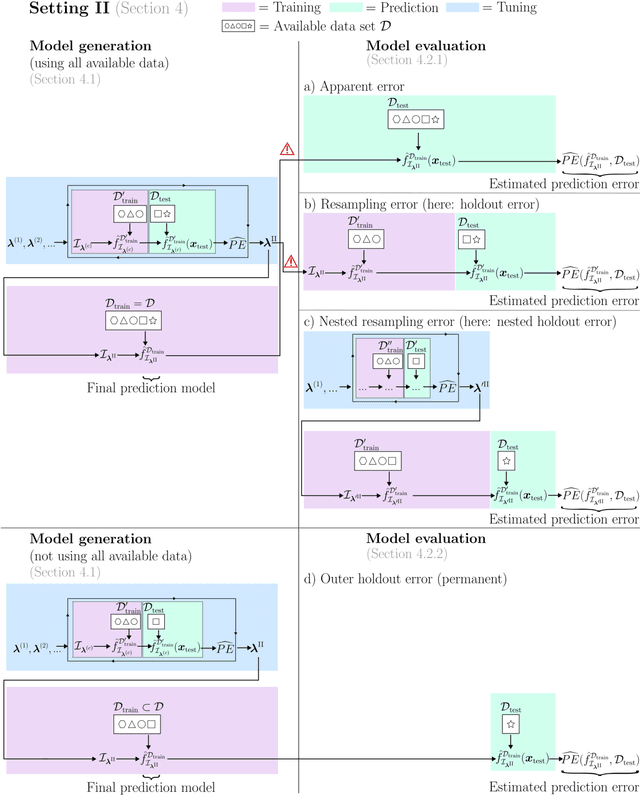
Adequately generating and evaluating prediction models based on supervised machine learning (ML) is often challenging, especially for less experienced users in applied research areas. Special attention is required in settings where the model generation process involves hyperparameter tuning, i.e. data-driven optimization of different types of hyperparameters to improve the predictive performance of the resulting model. Discussions about tuning typically focus on the hyperparameters of the ML algorithm (e.g., the minimum number of observations in each terminal node for a tree-based algorithm). In this context, it is often neglected that hyperparameters also exist for the preprocessing steps that are applied to the data before it is provided to the algorithm (e.g., how to handle missing feature values in the data). As a consequence, users experimenting with different preprocessing options to improve model performance may be unaware that this constitutes a form of hyperparameter tuning - albeit informal and unsystematic - and thus may fail to report or account for this optimization. To illuminate this issue, this paper reviews and empirically illustrates different procedures for generating and evaluating prediction models, explicitly addressing the different ways algorithm and preprocessing hyperparameters are typically handled by applied ML users. By highlighting potential pitfalls, especially those that may lead to exaggerated performance claims, this review aims to further improve the quality of predictive modeling in ML applications.