 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilling in the details: Perceiving from low fidelity images
Apr 14, 2016
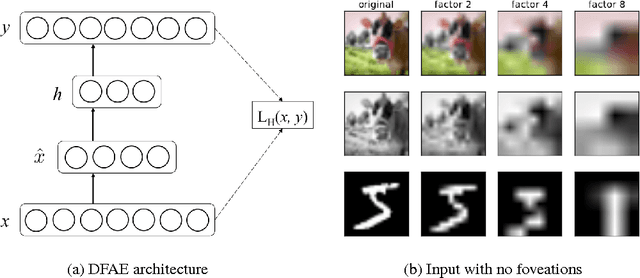
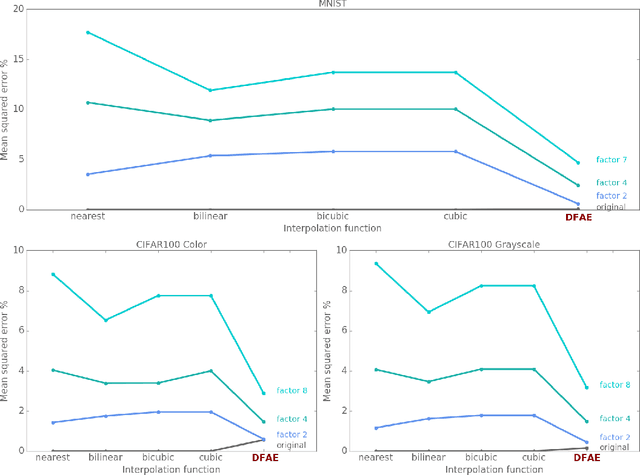

Humans perceive their surroundings in great detail even though most of our visual field is reduced to low-fidelity color-deprived (e.g. dichromatic) input by the retina. In contrast, most deep learning architectures are computationally wasteful in that they consider every part of the input when performing an image processing task. Yet, the human visual system is able to perform visual reasoning despite having only a small fovea of high visual acuity. With this in mind, we wish to understand the extent to which connectionist architectures are able to learn from and reason with low acuity, distorted inputs. Specifically, we train autoencoders to generate full-detail images from low-detail "foveations" of those images and then measure their ability to reconstruct the full-detail images from the foveated versions. By varying the type of foveation, we can study how well the architectures can cope with various types of distortion. We find that the autoencoder compensates for lower detail by learning increasingly global feature functions. In many cases, the learnt features are suitable for reconstructing the original full-detail image. For example, we find that the networks accurately perceive color in the periphery, even when 75\% of the input is achromatic.