 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Attributes to Natural Language: A Survey and Foresight on Text-based Person Re-identification
Jul 31, 2024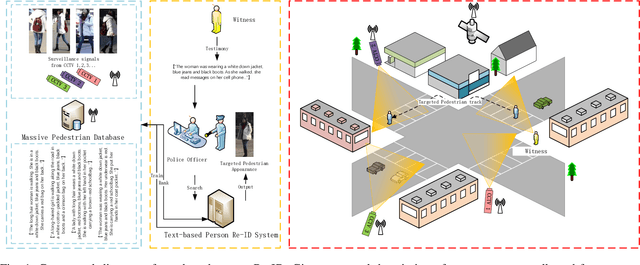
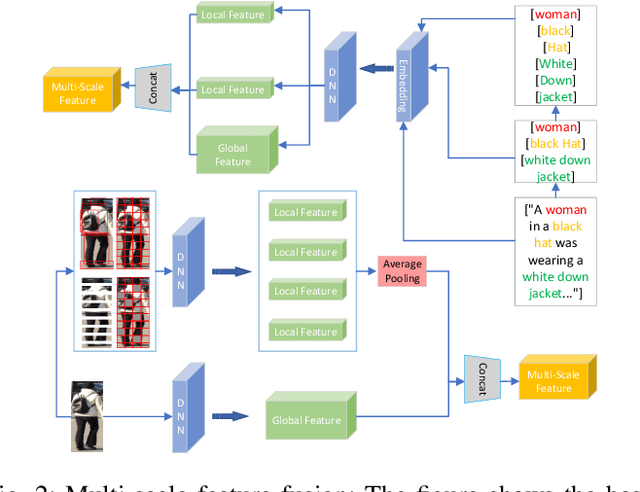
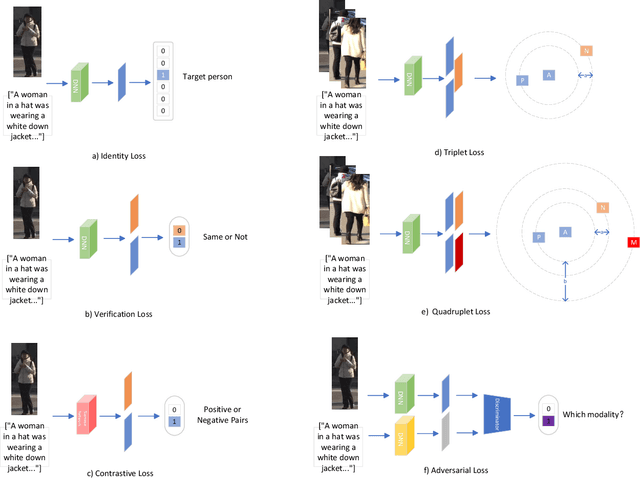
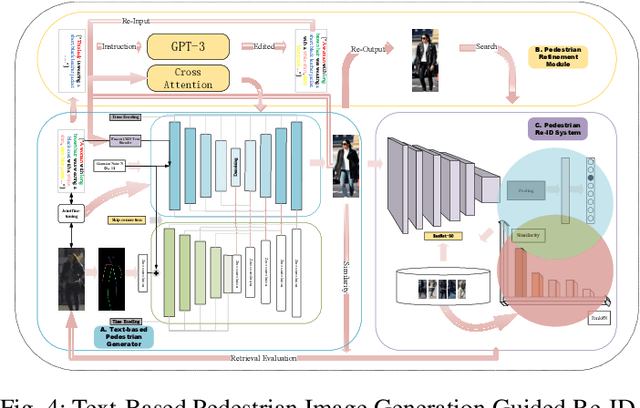
Text-based person re-identification (Re-ID) is a challenging topic in the field of complex multimodal analysis, its ultimate aim is to recognize specific pedestrians by scrutinizing attributes/natural language descriptions. Despite the wide range of applicable areas such as security surveillance, video retrieval, person tracking, and social media analytics, there is a notable absence of comprehensive reviews dedicated to summarizing the text-based person Re-ID from a technical perspective. To address this gap, we propose to introduce a taxonomy spanning Evaluation, Strategy, Architecture, and Optimization dimensions, providing a comprehensive survey of the text-based person Re-ID task. We start by laying the groundwork for text-based person Re-ID, elucidating fundamental concepts related to attribute/natural language-based identification. Then a thorough examination of existing benchmark datasets and metrics is presented. Subsequently, we further delve into prevalent feature extraction strategies employed in text-based person Re-ID research, followed by a concise summary of common network architectures within the domain. Prevalent loss functions utilized for model optimization and modality alignment in text-based person Re-ID are also scrutinized. To conclude, we offer a concise summary of our findings, pinpointing challenges in text-based person Re-ID. In response to these challenges, we outline potential avenues for future open-set text-based person Re-ID and present a baseline architecture for text-based pedestrian image generation-guided re-identification(TBPGR).