 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTERMS-Bench: Diagnosing LLM Negotiation Agents Beyond Deal Rate
May 13, 2026Negotiation is a central mechanism of economic exchange, shaping markets, procurement, labor agreements, and resource allocation. It is also a canonical testbed for agentic language models, requiring multi-turn interaction under hidden preferences, strategic communication, and binding constraints. These properties make negotiation hard to evaluate: unlike math or code, it has no intrinsic verifier. Existing LLM negotiation evaluations rely on LLM-vs.-LLM interaction or aggregate outcomes such as deal rate, leaving failures opaque. We introduce Terms-Bench, short for Testbed for Economic Reasoning in Multi-turn Strategy, a Bayesian-game framework that makes the environment itself the verifier by specifying the counterpart's latent type, policy, and payoff structure. We instantiate it in bilateral price negotiation, where the counterpart's private state and simulator policy are hidden from the agent but observable to the evaluator. This turns the counterpart from a black-box opponent into a diagnostic instrument, enabling agent-attributable failure analysis and oracle-reference optimality gaps. Evaluating 13 LLM agents spanning frontier systems from major providers, Terms-Bench turns negotiation evaluation from aggregate ranking into actionable diagnosis: where agents fail, why they fail, and what to strengthen. Empirically, frontier models saturate deal rate yet diverge in surplus extraction, cue use, belief calibration, and compliance, revealing agent-specific bargaining bottlenecks masked by prior benchmarks.
Optimizer-Induced Mode Connectivity: From AdamW to Muon
May 11, 2026Mode connectivity has been widely studied, yet the role of the optimizer remains underexplored. We revisit it through optimizer-induced implicit regularization, asking how connectivity behaves when restricted to solutions constrained by a given optimizer. For two-layer ReLU networks, we show that solutions from a single optimizer -- AdamW, Muon, or others in the Lion-$\mathcal{K}$ family -- form a connected set at sufficiently large width, a result not implied by prior work. We then characterize how optimizer-induced regions interact: at large width two different regions can be disjoint or overlap depending on regularization, while in our small-width example AdamW and Muon converge to disconnected zero-loss components separated by a provable loss barrier. Empirically, in GPT-2 pretraining, we observe same-optimizer paths preserve each model's spectrum while cross-optimizer paths traverse a smooth transition. Our results reveal optimizer-dependent structure beyond classical mode connectivity literature.
Statsformer: Validated Ensemble Learning with LLM-Derived Semantic Priors
Jan 29, 2026We introduce Statsformer, a principled framework for integrating large language model (LLM)-derived knowledge into supervised statistical learning. Existing approaches are limited in adaptability and scope: they either inject LLM guidance as an unvalidated heuristic, which is sensitive to LLM hallucination, or embed semantic information within a single fixed learner. Statsformer overcomes both limitations through a guardrailed ensemble architecture. We embed LLM-derived feature priors within an ensemble of linear and nonlinear learners, adaptively calibrating their influence via cross-validation. This design yields a flexible system with an oracle-style guarantee that it performs no worse than any convex combination of its in-library base learners, up to statistical error. Empirically, informative priors yield consistent performance improvements, while uninformative or misspecified LLM guidance is automatically downweighted, mitigating the impact of hallucinations across a diverse range of prediction tasks.
Active Learning of Deep Neural Networks via Gradient-Free Cutting Planes
Oct 03, 2024Active learning methods aim to improve sample complexity in machine learning. In this work, we investigate an active learning scheme via a novel gradient-free cutting-plane training method for ReLU networks of arbitrary depth. We demonstrate, for the first time, that cutting-plane algorithms, traditionally used in linear models, can be extended to deep neural networks despite their nonconvexity and nonlinear decision boundaries. Our results demonstrate that these methods provide a promising alternative to the commonly employed gradient-based optimization techniques in large-scale neural networks. Moreover, this training method induces the first deep active learning scheme known to achieve convergence guarantees. We exemplify the effectiveness of our proposed active learning method against popular deep active learning baselines via both synthetic data experiments and sentimental classification task on real datasets.
Newton Meets Marchenko-Pastur: Massively Parallel Second-Order Optimization with Hessian Sketching and Debiasing
Oct 02, 2024
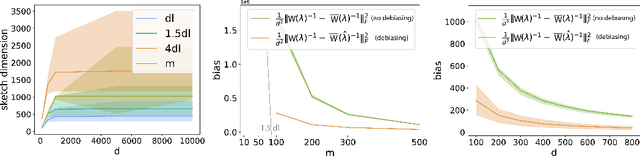

Motivated by recent advances in serverless cloud computing, in particular the "function as a service" (FaaS) model, we consider the problem of minimizing a convex function in a massively parallel fashion, where communication between workers is limited. Focusing on the case of a twice-differentiable objective subject to an L2 penalty, we propose a scheme where the central node (server) effectively runs a Newton method, offloading its high per-iteration cost -- stemming from the need to invert the Hessian -- to the workers. In our solution, workers produce independently coarse but low-bias estimates of the inverse Hessian, using an adaptive sketching scheme. The server then averages the descent directions produced by the workers, yielding a good approximation for the exact Newton step. The main component of our adaptive sketching scheme is a low-complexity procedure for selecting the sketching dimension, an issue that was left largely unaddressed in the existing literature on Hessian sketching for distributed optimization. Our solution is based on ideas from asymptotic random matrix theory, specifically the Marchenko-Pastur law. For Gaussian sketching matrices, we derive non asymptotic guarantees for our algorithm which are essentially dimension-free. Lastly, when the objective is self-concordant, we provide convergence guarantees for the approximate Newton's method with noisy Hessians, which may be of independent interest beyond the setting considered in this paper.
Spectral Adapter: Fine-Tuning in Spectral Space
May 22, 2024Recent developments in Parameter-Efficient Fine-Tuning (PEFT) methods for pretrained deep neural networks have captured widespread interest. In this work, we study the enhancement of current PEFT methods by incorporating the spectral information of pretrained weight matrices into the fine-tuning procedure. We investigate two spectral adaptation mechanisms, namely additive tuning and orthogonal rotation of the top singular vectors, both are done via first carrying out Singular Value Decomposition (SVD) of pretrained weights and then fine-tuning the top spectral space. We provide a theoretical analysis of spectral fine-tuning and show that our approach improves the rank capacity of low-rank adapters given a fixed trainable parameter budget. We show through extensive experiments that the proposed fine-tuning model enables better parameter efficiency and tuning performance as well as benefits multi-adapter fusion. The code will be open-sourced for reproducibility.
Riemannian Preconditioned LoRA for Fine-Tuning Foundation Models
Feb 07, 2024In this work we study the enhancement of Low Rank Adaptation (LoRA) fine-tuning procedure by introducing a Riemannian preconditioner in its optimization step. Specifically, we introduce an $r\times r$ preconditioner in each gradient step where $r$ is the LoRA rank. This preconditioner requires a small change to existing optimizer code and creates virtually minuscule storage and runtime overhead. Our experimental results with both large language models and text-to-image diffusion models show that with our preconditioner, the convergence and reliability of SGD and AdamW can be significantly enhanced. Moreover, the training process becomes much more robust to hyperparameter choices such as learning rate. Theoretically, we show that fine-tuning a two-layer ReLU network in the convex paramaterization with our preconditioner has convergence rate independent of condition number of the data matrix. This new Riemannian preconditioner, previously explored in classic low-rank matrix recovery, is introduced to deep learning tasks for the first time in our work. We release our code at https://github.com/pilancilab/Riemannian_Preconditioned_LoRA.
Analyzing Neural Network-Based Generative Diffusion Models through Convex Optimization
Feb 06, 2024



Diffusion models are becoming widely used in state-of-the-art image, video and audio generation. Score-based diffusion models stand out among these methods, necessitating the estimation of score function of the input data distribution. In this study, we present a theoretical framework to analyze two-layer neural network-based diffusion models by reframing score matching and denoising score matching as convex optimization. Though existing diffusion theory is mainly asymptotic, we characterize the exact predicted score function and establish the convergence result for neural network-based diffusion models with finite data. This work contributes to understanding what neural network-based diffusion model learns in non-asymptotic settings.