Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Task Agnostic Skills with Data-driven Guidance
Aug 04, 2021

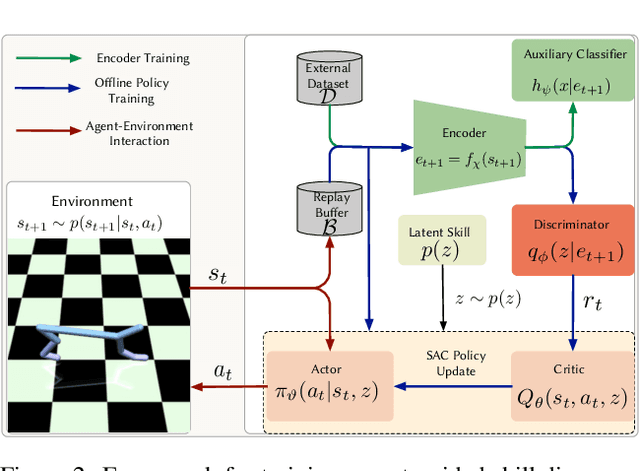

To increase autonomy in reinforcement learning, agents need to learn useful behaviours without reliance on manually designed reward functions. To that end, skill discovery methods have been used to learn the intrinsic options available to an agent using task-agnostic objectives. However, without the guidance of task-specific rewards, emergent behaviours are generally useless due to the under-constrained problem of skill discovery in complex and high-dimensional spaces. This paper proposes a framework for guiding the skill discovery towards the subset of expert-visited states using a learned state projection. We apply our method in various reinforcement learning (RL) tasks and show that such a projection results in more useful behaviours.
* ICML 2021 Workshop on Unsupervised Reinforcement Learning
(https://openreview.net/forum?id=CPh9DeHv08U)
Via