 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Frequency-Domain Feature Modeling for HRTF Magnitude Upsampling
Feb 12, 2026Accurate upsampling of Head-Related Transfer Functions (HRTFs) from sparse measurements is crucial for personalized spatial audio rendering. Traditional interpolation methods, such as kernel-based weighting or basis function expansions, rely on measurements from a single subject and are limited by the spatial sampling theorem, resulting in significant performance degradation under sparse sampling. Recent learning-based methods alleviate this limitation by leveraging cross-subject information, yet most existing neural architectures primarily focus on modeling spatial relationships across directions, while spectral dependencies along the frequency dimension are often modeled implicitly or treated independently. However, HRTF magnitude responses exhibit strong local continuity and long-range structure in the frequency domain, which are not fully exploited. This work investigates frequency-domain feature modeling by examining how different architectural choices, ranging from per-frequency multilayer perceptrons to convolutional, dilated convolutional, and attention-based models, affect performance under varying sparsity levels, showing that explicit spectral modeling consistently improves reconstruction accuracy, particularly under severe sparsity. Motivated by this observation, a frequency-domain Conformer-based architecture is adopted to jointly capture local spectral continuity and long-range frequency correlations. Experimental results on the SONICOM and HUTUBS datasets demonstrate that the proposed method achieves state-of-the-art performance in terms of interaural level difference and log-spectral distortion.
Permutation-Invariant Physics-Informed Neural Network for Region-to-Region Sound Field Reconstruction
Jan 27, 2026Most existing sound field reconstruction methods target point-to-region reconstruction, interpolating the Acoustic Transfer Functions (ATFs) between a fixed-position sound source and a receiver region. The applicability of these methods is limited because real-world ATFs tend to varying continuously with respect to the positions of sound sources and receiver regions. This paper presents a permutation-invariant physics-informed neural network for region-to-region sound field reconstruction, which aims to interpolate the ATFs across continuously varying sound sources and measurement regions. The proposed method employs a deep set architecture to process the receiver and sound source positions as an unordered set, preserving acoustic reciprocity. Furthermore, it incorporates the Helmholtz equation as a physical constraint to guide network training, ensuring physically consistent predictions.
A Distributed Algorithm for Personal Sound Zones Systems
Nov 21, 2023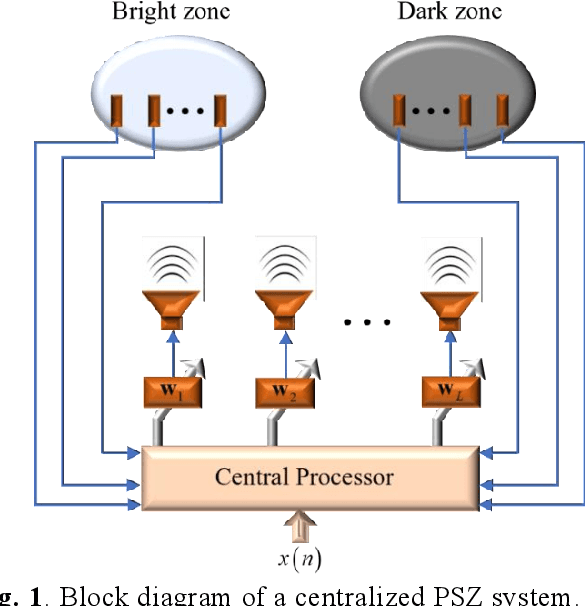
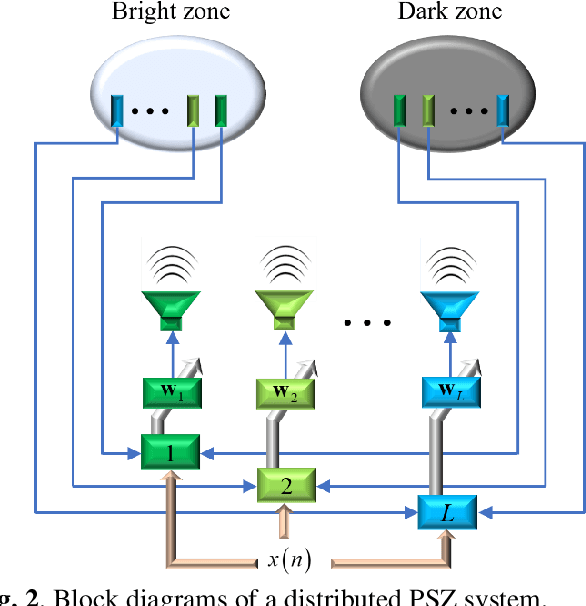
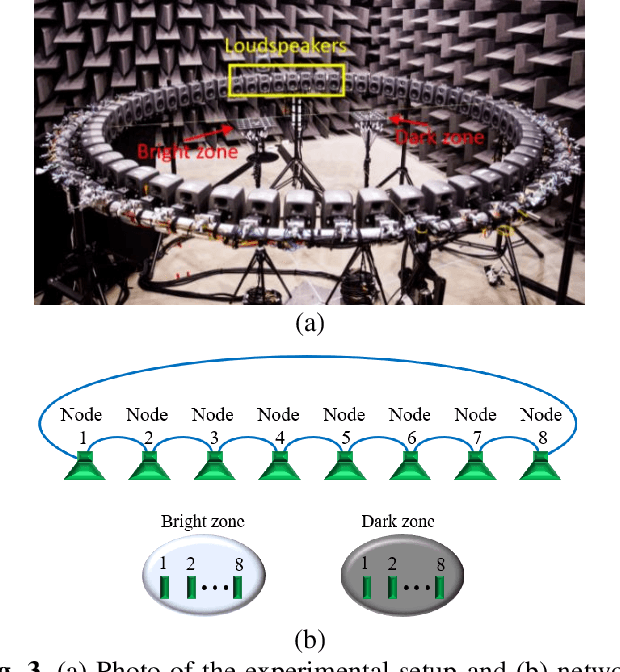
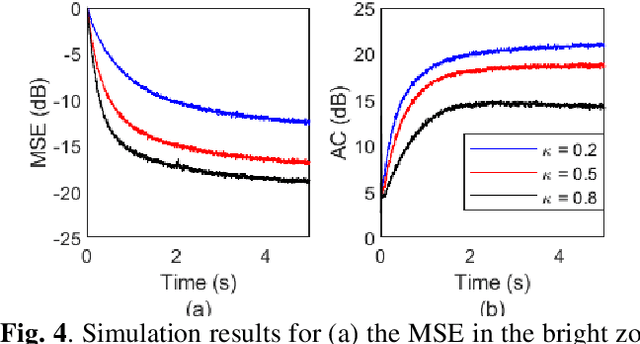
A Personal Sound Zones (PSZ) system aims to generate two or more independent listening zones that allow multiple users to listen to different music/audio content in a shared space without the need for wearing headphones. Most existing studies assume that the acoustic paths between loudspeakers and microphones are measured beforehand in a stationary environment. Recently, adaptive PSZ systems have been explored to adapt the system in a time-varying acoustic environment. However, because a PSZ system usually requires multiple loudspeakers, the multichannel adaptive algorithms impose a high computational load on the processor. To overcome that problem, this paper proposes an efficient distributed algorithm for PSZ systems, which not only spreads the computational burden over multiple nodes but also reduces the overall computational complexity, at the expense of a slight decrease in performance. Simulation results with true room impulse responses measured in a Hemi-Anechoic chamber are performed to verify the proposed distributed PSZ system.